In most references describing the process of good problem solving, the first real step is to explain what actually is the problem.
It is easy to get tripped up at this stage and describe the problem in terms of the desired target, or in terms of “lack of” a specific countermeasure. That, of course, skips over the whole point of gaining a deep understanding of the situation before moving too far into intestigating causes.
I heard a great way to frame that first bit of description tonight from Richard.
“What is the evidence of a problem?”
That word, “evidence” does a much better job of conveying the point that this should be a description of the things that are observed, heard, felt, etc. rather than any kind of analysis.
In many cases a “big problem” is actually evidence of many small ones. “Too much inventory” is one of those. So is “defect rates” or any other aggregated measure. If you are running KPIs you probably know that, because they aggregate so much, they are often relatively insensitive until things are so far into the hole that it is a mess to untangle. Better to instrument your processes at much finer levels and get “evidence” in real time.
But what, exactly, are “the basics” of the Toyota Production System?
This is critically important. Permit me to cite an analogy.
Look at a house. What do you see? What would you say are “the basics?”
At first glance, all houses have walls, a roof. They have a door. They are divided into rooms for various activities and purposes. A “basic house” is going to have an entry, a living room, a kitchen, a couple of bedrooms, a bathroom. More complex houses will have more rooms, fancier architecture, higher grades of materials, be bigger, but the basics are all there.
OK, that is a basic house.
I make this point because when people talk about the basics of “lean manufacturing” they talk about the things you can see. If I open up Learning to See, and turn to the “Green Tab” the chapter’s title is “What Makes A Value Stream Lean.” That chapter is primarily (right after the talk about waste and overproduction) a list and description of “Characteristics of a Lean Value Stream.”
Produce to your takt time.
Develop continuous flow wherever possible.
Use supermarkets to control production where continuous flow does not extend upstream.
Try to send the customer schedule to only one production process.
Distribute the production of different products over time at the pacemaker process (level the production mix).
Create an “initial pull” by releasing and withdrawing small, consistent increments of work at the pacemaker process. (Level the production volume).
Develop the ability to make “every part every day” (then every shirt, then every hour or pallet or pitch) in fabrication processes upstream of the pacemaker process.
Now I have to say right now that I have always loved this chapter. I cannot count the number of people I have referred to “The Green Tab” as a fundamental primer. It includes all of the basics, just like our house.
In their latest book, Kaizen Express, the LEI has brought out some more detail on these same points, and added a few “rooms” to the house. One critical aspect they add is various topics that add up to quality. (It’s kind of like leaving out the kitchen or the bathroom if you don’t mention that.) They talk about zone control, line stop, and countermeasures to quality problems. (I will do a full review on this book soon.)
Then on page 99 starts four pages on Employee Involvement where they talk about practical kaizen training (PKT), and suggestion programs.
Let’s go back to our house. The things we said were “the basics” were the things you see when you look at it from the street, and go inside and walk around in it. But in an industrialized country, the modern single family residence is a miracle of accumulated knowledge and technology. The basics are the things that keep it from sinking into the ground, from catching on fire, from leaking and rotting. They are the things you can’t see, but unless you understand them, your house may look like the one next door, but it won’t perform like the one next door.
I have been in dozens of factories that had takt time, some semblance of continuous flow, pull systems, supermarkets, all of that stuff. They had run hundreds, maybe thousands, of kaizen events, and had suggestion programs. All of these things were visible just by walking around.
Yet most of them were stuck. They had reached a point when all of their energy was being expended to re-implement the things that had slid back. Three steps forward, three steps back.
They had read Ohno’s book, they knew the history of the Toyota Production System. They understood all of the engineering aspects of the system, and could install very good working examples of all of it.
But something wasn’t there, and that something is the foundation that keeps the house from sinking into the ground. It is the real basics.
Kaizen Express hints at it on pages 99 – 102, it is true employee involvement. And here is a real basic: Employee involvement is created by leader involvement. Not just top leaders, all leaders, at all levels.
To be honest, a lot of technical specialists don’t like that very much for a couple of reasons. First, engaging the leaders, at all levels, is really hard. It is a lot easier to get things done by going straight to the gemba and doing it ourselves – we show people how to do it, we “engage” them in the initial implementation, and everything is wonderful for the Friday report-out.
But I contend that the foundation of the Toyota Production System is the leadership system. It is the system of leadership that holds up all of the walls that we call takt, flow and pull. Those things, in turn, enable the leadership system to function better. The “characteristics of a lean value stream” evolved in response to the leadership system, in order to strengthen it. It is a symbiosis, an ecosystem.
“But it didn’t start out as a leadership system.” No, it did not. The history of how the Toyota Production System evolved is well documented, and the leadership system was less designed than it evolved. But let’s go back to our house analogy.
Primitive houses only have the “basics” I described above. They don’t have sophisticated foundations, some are just built on skids (if that). But because they lack the basics, most of those primitive houses don’t last.
And there is the paradox. When we say “back to the basics” we cannot only refer to the chronological history of how the system developed. We have to take the most successful, most robust example in front of us today, and we have to look at what fundamental thing holds this thing up and lets it grow more robust every day.
So let’s take a look at what Toyota teaches when they teach someone the basics.
The article Learning to Lead at Toyota was written back in 2004, but I still feels it offers a lot of un-captured insight into the contrast between what Toyota thinks are “the basics” and what most others do. I want to encourage everyone to get a copy, and not just read it, but to parse it, study it, and use it as an “ideal condition” or a benchmark. Compare your “lean manufacturing” and your leadership systems to what is described in here. Ask yourself the question:
Do we really understand the basics?
Note: There are now links to my study guides for Learning to Lead at Toyota on the Resources page.
A couple of posts ago, I tried to emphasize “hypothesis testing” as the key, core thinking behind the TPS. For that matter, I think that anyone who truly understands any of the various improvement approaches out there will find the same thinking at the core. Certainly Six Sigma; Theory of Constraints; and TQM are all about surfacing and solving problems. They may use different language, might insert the initial lever between different bricks, but in the end, the approaches all embrace the same basic thinking.
I’d like to put out there an idea that it is the way problems are regarded and approached that separates “gets it” from “business as usual.”
What Constitutes “a problem?”
In “traditional thinking” a problem is something which disrupts output. It is something serious enough that it cannot be ignored.
In a true continuous improvement mindset, anything that causes variation from the plan, in any way, is “a problem.” Any barrier between the current condition and the idealized world is “a problem.”
What triggers a response?
In “traditional thinking” if output isn’t disrupted, spend time elsewhere. There is a caveat to this, however. The parable of the “boiling frog” (whether true for actual frogs or not) can drive an ever higher level of numbness as “normalized deviance” sets in.
Since continuous improvement is a process of discovering the ideal process, variation from the plan is new information. It must be investigated and understood. If everything is running smoothly, then the problem solving shifts to the next barrier to higher performance.
What triggers alarm in the organization?
This one may be the most controversial. While “stopped production” is certainly cause for alarm and immediate response, in the traditional thinking world, it is the only thing that really gets people’s attention.
In a thinking and learning organization, I would add to the above “No problems are apparent.” If there are no andons, there are no defects, there are no line stops, there are no shortages, there are no disruptions, then there is a BIG problem. I say that because these conditions are impossible and it is only because your system is totally numb that you would not see them.
Target Condition
Given the above, then I think it is safe to offer that silence is equated with “stability” in the traditionally reacting organization. Of course it isn’t stable at all, it is just that there is so much systemic anesthesia that nobody feels anything.
In the continuous improvement mindset, things are running as they should if there is a continuous flow of problem being surfaced and solved. That is the only way to be 100% certain that things are getting better every day.
“Management Commitment”
The term “management commitment” is tossed around as a prime reason for failure of improvement initiatives. There are lots of good reasons for this, but until we really define exactly what leaders need to do every day, stop using euphemisms, and start getting real about leadership’s actual role in this process, we are crutching the problem. This is partly “our fault” because we teach the basics very badly. We put top leaders into “kaizen events” but never explicitly link kaizen to daily problem solving. In doing so, we convince them that if only they support enough kaizen events, the organization will be transformed. The logical result is a monthly report on how many kaizen events have been run. Argh.
If we used kaizen events to explicitly teach the core questions, the rules of good process design, and the concept of applying PDCA to everything, we might get more traction. That can be difficult, but maybe if everyone in the industry starts thinking in terms of a few core mantras we might get a chorus going.
Kris Hallan is a frequent contributor on the LEI forum at lean.org.
In this post, he outlines some great experiences with trying to implement the “A3 process” in his organization. Lean Forums – A3.
One thing that really drove home what goes wrong most of the time with the A3 process, and frankly, with most well-intentioned efforts to bring good analysis into organizations, was his experience of an early effort to try to “require” it without having the behaviors to back it up:
One of the worst things you can do is require an A3 be written and then allow a poor A3 to get past you. This has a tendency to happen when you put an A3 mandate on something that you don’t necessarily have control over. For instance, we started by requiring all CAPEX [capital expenditure – ed] projects to be proposed using the A3 format (hoping that the A3 thought process would come with the format).
What we got was a lot of projects summarized on A3s and virtually no feedback to go back and improve anything. No one learned anything from the process, no hanei occured, and nemawashi was non-existent. It became a box that everyone had to check. This can have a very detrimental effect on people’s attitude toward A3. Since they don’t take it seriously, they can’t really learn anything from it. I would say that this actually moved us backwards in our understanding of problem solving.
I could not agree more. I have seen this in other companies. This is PLAN-DO without the CHECK and ACTion. Set an expectation, go through the motions of compliance, but don’t ever bother to see if it is actually working the way that is expected.
The good news, further into his post, is that Kris’s organization figured it out and found that doing it thoroughly is more important (and quicker!) than doing it fast.
In past posts, I have referred to an organization that implemented a “morning market” as a way to manage their problem solving efforts.
Synchronicity being what it is:
Barb, the driving force in the organization in my original story, wrote to tell me that their morning market is going strong – and remains the centerpiece of their problem solving culture. In 2008, she reports, their morning market drove close to 2000 non-trivial problems to ground. That is about 10/day. How well do you do?
Edited to add in March 2015: I heard from Barb again. It is still a core part of the organization’s culture.
So – to organizations trying to implement “a problem solving culture” and anyone else who is interested, I am going to get into some of the nuts and bolts of what we did there way back in 2003. (I am telling you when so that it sinks in that this is a change that has lasted and fundamentally altered the culture there.)
What is “A Morning Market?”
The term comes from Masaaki Imai’s book Gemba Kaizen pages 114 – 118. It is a short section, and does not give a lot of detail. The idea is to review defects “first thing in the morning when they are fresh” – thus the analogy to the early morning fish and produce markets. (For those who like Japanese jargon, the term is asaichi, but in general, with an English speaking audience, I prefer to use English terms.)
The concept is to display the actual defects, classified by what is known about them.
‘A’ problems: The cause is known. Countermeasures can be implemented immediately.
‘B’ problems: The cause is known, countermeasures are not known.
‘C’ problems: Cause is unknown.
Each morning the new defects are touched, felt, understood. (The actual objects). Then the team organizes to solve the problem. The plant manager should visit all of the morning markets so he can keep tabs on the kinds of problems they are seeing.
Simple, eh?
Putting It Into Practice
Fortunately we were not the pioneers within the company. That honor goes to another part of the company who was more than willing to share what they had learned, but their key lesson was “put two pieces of tape on a table, divide it into thirds, label them A, B and C and just try it.”
They were right – as always, it is impossible to design a perfect process, but it is possible to discover one. Some key points:
There is a meeting, and it is called “the morning market” but the meeting does not get the problems solved. The difference between the organizations that made this work and the ones that didn’t was clear: To make it work it is vital to carve out dedicated time for the problem solvers to work on solving problems. It can’t be a “when you get around to it” thing, it must be purposeful, organized work.
The meeting is not a place to work on solving problems. There is a huge temptation to discuss details, ask questions, try to describe problems, make and take suggestions about what it might be, or what might be tried. It took draconian facilitation to keep this from happening.
The purpose of the meeting is to quickly review the status of what is being worked on, quickly review new problems that have come up, and quickly manage who is working on what for the next 24 hours. That’s it.
The morning market must be an integral part of an escalation process. The purpose is to work on real problems that have actually happened. Work on them as they come up.
Just Getting Started
This was all done in the background of trying to implement a moving assembly line. There is a long back story there, but suffice it to say that the idea of a “line stop” was just coming into play. Everyone knew the principle of stopping the line for problems, but there was no real experience with it. As the line was being developed, there were lots of stops just to determine the work sequence and timing. But now it was in production.
The first point of confusion was the duration of a line stop. Some were under the impression that the line would remain stopped until the root cause of the problem was understood. “No, the line remains stopped until the problem can be contained,” meaning that safe operations that assure quality are in place.
The escalation process evolved, and for the first time in a long time, manufacturing engineers started getting involved in manufacturing.
The actual morning market meeting revolved around a whiteboard. At least at first. When they started, they filled the board with problems in a day or two. They called and said they wanted to start a computer database to track the problems. I told them “get another board.” In a few days that board, too, filled up. It really made sense now to start a computer database. Nope. “Get another board.” That board started to fill.
Then something interesting happened. They started clearing problems.
PDCA – Refining The Process
The tracking board evolved a little bit over time.
The first change was to add a discrete column that called out what immediate measures had been taken to contain the problem and allow safe, quality production to resume. This was important for two reasons.
First, it forced the team to distinguish between the temporary stop-gap measure that was put in immediately and the true root-cause / countermeasure that could, and would, come later. Previously the culture had been that once this initial action were taken, things were good. We deliberately called these “containments” and reserved the word “countermeasure” for the thing that actually addressed root cause. This was just to avoid confusion, there is no dogma about it.
Second, it reminded the team of what (probably wasteful) activity they should be able to remove from the process when / if the countermeasure actually works. This helped keep these temporary fixes from growing roots.
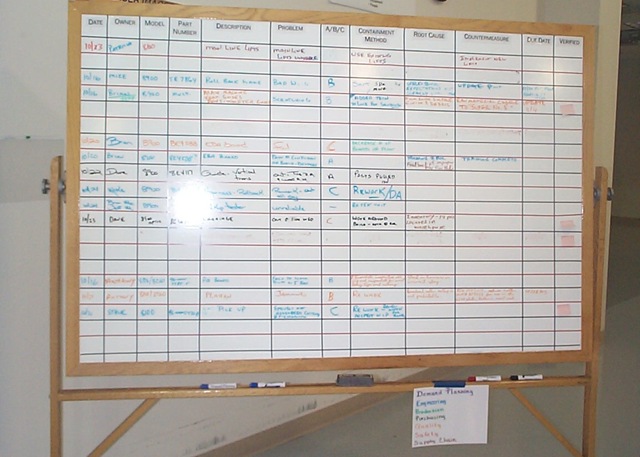
You can get an idea of what a typical problem board looked like here:
The columns were:
Date (initial date the problem was encountered)
Owner
Model (the product)
Part Number (what part was involved)
Description (of the part)
Problem (description of the problem)
A/B/C (which of the above categories the problem was now. Note that it can change as more is learned.
Containment Method
Root Cause (filled in when learned)
Countermeasure (best known being tried right now)
Due Date (when next action is due / reported)
Verified (how was the countermeasure verified as effective?)
A key point is that last column: Verified. The problem stays on the board until there is a verified countermeasure in place. That means they actually tested the countermeasure to make sure it worked. This is, for a lot of organizations, a big, big change. All too many take some action and “call it good.” Fire and forget. This little thing started shifting the culture of the organization toward checking things to make sure they did what they were thought to do.
Refining The Meeting
While this particular shop floor was not excessively loud, it was too loud for an effective meeting of more than 3-4 people. Rather than moving the meeting to a conference room, the team spent $50 at Wally World and bought a karaoke machine. This provided a nice, inexpensive P.A. system. It added the benefit that the microphone became a “talking stick” – it forced people to pay attention to one person at a time.
Developing Capability
The other gap in the process that emerged pretty quickly was the capability of the organization to solve problems. While there had been a Six Sigma program in place for quite a while, most of skill revolved around the kinds of problems that would classify as “black belt projects.” The basic troubleshooting and physical investigation skills were lacking.
After exploring a lot of options, the organization’s countermeasure was to adopt a standard packaged training program, give it to the people involved in working the problems, then expecting that they immediately start using the method. This, again, was a big change over most organization’s approach to training as “interesting.” In this case, the method was not only taught, it was adopted as a standard. That was a big help. A key lesson learned was that, rather than debate which “method” was better, just pick one and go. In the end, they are all pretty much the same, only the vocabulary is different.
Spreading The Concept
In this organization, the two biggest “hitters” every day were supplier part quality and supplier part shortages. This was pretty much a final-assembly and test only operation, so they were pretty vulnerable to supplier issues. This process drove a systematic approach to understand why the received part was defective vs. just replacing it. Eventually they started taking some of their quality assurance tools upstream and teaching them to key suppliers. Questions were asked such as “How can we verify this is a good part before the supplier ships it?” They also started acknowledging design and supplier capability (vs. just price and capacity) issues.
On the materials side, the supply chain people started their own morning market to work on the causes of shortages. I have covered their story here.
As they implemented their kanban system, morning markets sprang up in the warehouse to address their process breakdowns. Another one addressed the pick-and-delivery process that got kits to the line. Lost cards were addressed. Rather than just update a pick cart, there was interest in why they got it wrong in the first place, which ended up addressing bill-of-material issues, which, in turn, made the record more robust.
Managing The Priorities
Of course, at some point, the number of problems encountered can overwhelm the problem solvers. The next evolution replaced the white board with “problem solving strips.” These were strips of paper, a few inches high, the width of the white board, with the same columns on them (plus a little additional administrative information). This format let the team move problems around on the wall, group them, categorize them, and manage them better. Related issues could be grouped together and worked together. Supplier and internal workmanship issues could be grouped on the wall, making a good visual indication of where the issues were.
“Problem Strips” at the meeting.
But those were all side effects. The key was managing the workload.
Any organization has a limited capacity to work on stuff. The previous method of assignment had been that every problem was assigned to someone on the first day it was reviewed. It became clear pretty quickly that the half a dozen people actually doing the work were getting a little sick of being chided for not making any progress on problems 3, 4 and 5 because they were working on 1 and 2. In effect, the organization was leaving the prioritization to the problem solvers, and then second guessing their choices. This is not respectful of people.
The countermeasure – developed by the shop floor production manager, was to put the problems on the strips discussed above. The reason she did it was to be able to maintain an “unassigned” queue.
Any problem which was not being worked on was in the unassigned queue on the wall. All of the problems were captured, all were visible to everyone, but they recognized they couldn’t work on everything at once. As a technical person became available, he would pull the next problem from the queue.
There were two great things about this. First, the production manager could reshuffle the queue anytime she wanted. Thus the next one in line was always the one that she felt was the most important. This could be discussed, but ultimately it was her decision. Second is that the queue became a visual indicator that compared the rate of discovering problems (into the queue) with the rate of solving problems (out of the queue). This was a great “Check” on the capacity and capability of the organization vs. what they needed to do.
There were two, and only two, valid reasons for a problem to bypass this process.
There was a safety issue.
A defect had escaped the factory and resulted in a customer complaint.
In these cases, someone would be assigned to work on it right away. The problem that had been “theirs” was “parked.” This acknowledged the priority, rather than just giving him something else to do and expecting everything else to get done too. (This is respect for people.)
Incorporation of Other Tools
Later on, a quality inspection standard was adopted. Rather than making this something new, it was incorporated into the problem solving process itself. When a defect was found, the first step was to assess the process against the standard for the robustness of countermeasures. Not surprisingly, there was always a pretty significant gap between the level of countermeasures mandated by the standard and what was actually in place. The countermeasure was to bring the process up to the standard.
The standard itself classified a potential defect based on its possible consequences. For each of four levels, it specified how robust countermeasures should be for preventing error, detecting defects, checking the process, secondary checks and overall process review. Because it called out, not only technical countermeasures, but leadership standard work, this process began driving other thinking into the organization.
Effect On Designs
As you might imagine, there were a fair number of issues that traced back to the design itself. While it may have been necessary to live with some of these, there was an active product development cycle ongoing for new models. Some of the design issues managed to get addressed in subsequent designs, making them easier to “get right” in manufacturing.
What Was Left Out
The things that got onto the board generally required a technical professional to work them. These were not trivial problems. In fact, at first, they didn’t even bother with anything that stopped the line for less than 10 minutes (meaning they could rework / repair the problem and ship a good unit). But even though they turned this threshold down over time, there were hundreds of little things that didn’t get on the radar. And they shouldn’t… at least not onto this radar.
The morning market should address the things that are outside the scope of the shop floor work teams to address.
Another organization I know addressed these small problems really well with their organized and directed daily kaizen activity. Every day they captured everything that delayed the work. Five second stoppages were getting on to their radar. Time was dedicated every day at the end of the shift for the Team Members to work on the little things that tripped them up. They had support and resources – leadership that helped them, a work area to try out ideas, tools and materials to make all of the little gadgets that helped them make things better. They didn’t waste their time painting the floor, making things pretty, etc. unless that had been a source of confusion or other cause of delay. Although the engineers did work on problems as well, they did not have the work structure described above.
I would love to see the effect in an organization that does all of this at once.
No A3’s?
With the “A3” as all the rage today, I am sure someone is asking this question while reading this. No. We knew about A3’s, but the “problem solving strips” served about 75% of the purpose. Not everything, but they worked. Would a more formal A3 documentation have worked better? Not sure. This isn’t dogma. It is about applying sound, well thought out methodology, then checking to see if it is working as expected.
Summary
Is all of this stuff in place today? Honestly? I don’t know. [Update: As of the end of 2011, this process is still going strong and is strongly embedded as “the way we do things” in their culture.] And it was far from as perfect as I have described it. BUT organized problem solving made a huge difference in their performance, both tangible and intangible. In spite of huge pressure to source to low-labor areas, they are still in business. When I read “Chasing The Rabbit” I have to say that, in this case, they were almost there.
And finally, an epilogue:
This organization had a sister organization just across an alley – literally a 3 minute walk away. The sister organization was a poster-child for a “management by measurement” culture. The leadermanager person in charge sincerely believed that, if only he could incorporate the right measurements into his manager’s performance reviews, they would work together and do the right things. You can guess the result, but might not guess that this management team described themselves as “dysfunctional.” They tried to put in a “morning market” (as it was actually mandated to have one – something else that doesn’t work, by the way). There were some differences.
In the one that worked, top leaders showed up. They expected functional leaders to show up. The people solving the problems showed up. The meeting was facilitated by the assembly manager or the operations manager. After the meeting people stayed on the shop floor and worked on problems. Calendars were blocked out (which worked because this was a calendar driven culture) for shop floor problem solving. Over time the manufacturing engineers got to know the assemblers pretty well.
In the one that didn’t work, the meeting was facilitated conducted by a quality department staffer. The manufacturing engineers had other priorities because “they weren’t being measured on solving problems.” After the meeting, everyone went back to their desks and resumed what they had been doing.
There were a lot of other issues as well, but the bottom line is that “problem solving” took hold as “the way we do things” in one organization, and was regarded as yet another task in the other.
About 8 months into this, as they were trying, yet again, to get a kanban going, a group of supervisors came across the alley to see what their neighbors were doing. What they saw was not only the mechanics of moving cards and parts, but the process of managing problems. And the result of managing problems was that they saw problems as pointing them to where they needed to gain more understanding rather than problems as excuses. One of the supervisors later came to me, visibly shaken, with the quote “I now realize that these people work together in a fundamentally different way.” And that, in the end, was the result.
In the end? The organization in this story is still in business, still manufacturing things in a “high cost labor” market. The other one was closed down and outsourced in 2005.
aarrgh! all of the purists say! Death by PowerPoint. Yup.
But one of today’s realities is that many managers expect to be “briefed” and expect it to be done in a conference room with a projector and… PowerPoint.
Getting them to sit down and go through a single sheet of A3 paper is going to be a stretch at best. So let me propose an interim.
Five slides, six at the most.
No fancy headings, logos, etc. They take up space and distract from the message.
Simple text. No animation. Pictures, graphs to make the points.
The slides are:
Background / Current Condition
Briefly cover where we are, and why we are talking about this right now.
Back up your assertions with data and facts. Note that, in my context, a “fact” is something you can see, observe, sense, touch. The data must be explained by the facts.
Target
What is this going to look like when we are successful?
The target is binary. It is verifiable as “met” or “not met.” It does not include vague words like “improved” or “reduced” which are subject to interpretation.
Analysis
What is keeping us from hitting the target right now? What is in the way? What must be solved, what barrier must be cleared, what factor must be eliminated?
Clearly demonstrate that dealing with these issues will allow reaching the target.
Countermeasures / Implementation
What actions will be taken to deal with the issues or shortcomings?
When will they be taken?
Who will take them?
When will they be checked for successful implementation?
For each one, what is the predicted effect if it works as planned?
How will you check the actual effect?
Do the cumulative predicted effects of your countermeasures add up to enough to close the gap and reach the target?
If not, then what else are you going to do?
Results / Follow-Up
What actually happened?
If When things got off track, what is the recovery / correction plan?
If When actual results were different than planned, what else are you going to do?
Did you reach the target? If not, what else are you going to do?
It’s the thinking, not the format!
Do the headers change sometimes? Sure, but the intent is:
What is happening?
What do you want to happen?
What is the gap?
What will you do to get it there, and how will you check that:
You did you you planned.
It worked like you expected?
Do it.
Check it.
Fix it.
Learn.
PDCA
This is a leader’s tool
If it is done well, and done correctly, it is done the way John Shook describes it in his new book Managing to Learn. But don’t confuse the size of the paper with the structure of the thinking. Get that right. Worry about the sheet of paper later if you must.
When encountering resistance, a good teacher knows what things can be left for later, and which ones are critical to get right.
I hit around this issue in the past, but with the recent publication of John Shook’s new book Managing to Learn, I felt the need to go into it again.
In the text, Shook’s coverage of root cause investigation is very thorough. He tells the story of each “Why?” question triggering another round of investigation.
But in a full page sidebar, he uses the example from Taiichi Ohno’s classic book Toyota Production System: Beyond Large-Scale Production. For those of you following at home, the original example is on page 17 of Ohno’s book, and the reference to it is on page 47 of Managing to Learn.
Quoting from the books:
Why did the machine stop? There was an overload and the fuse blew.
Why was there an overload? The bearing was not sufficiently lubricated.
Why was it not lubricated sufficiently? The lubrication pump was not working sufficiently.
Why was it not pumping sufficiently? The shaft of the pump was warn and rattling.
Why was the shaft worn out? There was no strainer attached, and metal scrap got in.
The conclusion is that the lack of a strainer is the root cause of the machine stoppage. (“For the want of a nail…“)
This line of thinking is all well and good after the chain is understood. Unfortunately it gives the impression that the root cause of a problem can be reached simply by repeatedly asking “Why?” and writing down the answers. I know this because I have personally experienced well-meaning-but-ignorant consultants who have done exactly that on a flip chart with a team trying to solve a problem.
I have heard “Just ask why five times” as a method, proposed in contrast to more rigorous methods.
It ain’t that simple, folks.
Let’s look at this example.
Why did the machine stop? What I know right now is that the machine isn’t running. Although I can get to the “blown fuse” fairly quickly, let’s not confuse the first or second thing I would check with a process of systematically eliminating other possibilities. The simple fact is that I would check the fuse fairly quickly because I can’t check everything at once, and because I am going to check things more-or-less in order of simplicity. But I am systematically ruling out loss of power at the feed, a physical problem (such as a broken connection), a problem in the control circuitry, and a host of other possible issues. In short, I must investigate a “loss of electrical power” until I reach the conclusion that it is a blown fuse.
Ohno skips a bit by going directly to the cause of the blown fuse as an overload, but it is going to take a little more investigation to get to that conclusion. Coming forward a few decades from when that book was written, I would probably reset the breaker and see if it trips again. But even then, I haven’t ruled out a bad fuse / breaker. Determining, for sure, that it is an overload condition is going to take a little more troubleshooting. A multi-meter would be much more useful than a flip chart at this point.
Once I am pretty certain I am dealing with an overload condition, then I can ask what is causing it.
Why was there an overload? Well lots of things can cause an overload. Something is putting drag on this notional motor. Maybe it was a bearing problem in the motor. Maybe a bearing elsewhere. Maybe a gear has locked up. Is this even an overloaded motor? Or is it an overloaded circuit? Eventually, after systematically checking and testing, I find the bad bearing. Now – Why did the bearing fail? How do I know it is lack of lubrication? Hopefully it is obvious, but there may be some other things I need to look at. Is there a flow of lubricant into the bearing? If that is normal, I need to look elsewhere. But there is not a normal flow of lubricant, so for now I can reasonably assume that lubrication is the problem.
Why was it not lubricated sufficiently? If the lubricant is not reaching the bearing, Why is there insufficient lubricant flow?
Is the sump dry? Is the intake clear? Is the line kinked, clogged or leaking? Is it clear? How do I know? As I work my way upstream, physically checking, I’ll eventually reach the pump that is complaining.
Why was it not pumping sufficiently? At this point, I am probably replacing the pump. But why the pump failed in the first place is a reasonable question to be asking. And only upon physical examination of the old pump am I going to find the worn and rattling shaft. But I am curious, so I look rather than just scrapping the pump and replacing it.
Why was the shaft worn out? Because the scope of investigation is narrowing, things get a little easier. Taking the old pump apart is going to reveal that the shaft is bound up with metal scrap. That takes me through a few more “Why?” questions – how could this get in here? And that is the point where I see no strainer on the intake.
Now, obviously, I made all of this up. But here is my point:
We, the teachers of others, do our students a major disservice when we over-simplify things. “Ask why five times” is very easy for people to take it out of context and try to apply literally. Unless the problem is very simple, it just doesn’t work, and that leaves them:
Frustrated.
(Correctly) believing that anyone who thinks the real world is this simple has never had to deal with it.
Ohno certainly dealt in the real world. He also uses metaphors. We should caution ourselves not to take everything as 100% literal. Ohno’s point is summed up in the last paragraph of this section of his book on page 18 when he concludes:
In a production plant operation, data are highly regarded — but I consider facts to be even more important. When a problem arises, if our search for the cause is not thorough, the actions taken can be out of focus. That is why we repeatedly ask why. This is the scientific basis of the Toyota system. [emphasis added]
The scientific method generates understanding through repeated hypothesis testing. A scientist ask “Why?” then fits a possible answer to the facts as he understands them and then asks “What else would be true if I am right?” and builds an experiment (or investigates) to verify, or refute, his thinking. This is how to ask “Why” and this is what you should do five times.
Perhaps what you measure is what you get. More likely, what you measure is all you get. What you don’t (or can’t) measure is lost.
In his introduction to the book, Shook describes the contrast:
Where the laissez-faire, hands-off manager will content himself to set targets and delegate everything, essentially saying, “I don’t care how you do it, as long as you get the results,” the Toyota manager desperately wants to know how you’ll do it, saying “I want to hear everything about your thinking, tell me about your plans.”
and a little later:
This is a stark contrast to the results-only oriented management-by-numbers approach.
Shook then also references H. Thomas Johnson’s paper. (like minds?)
But I would like to dive a little deeper into the contrast of leadership cultures here.
Let’s say the “management by measurement” leader thinks there is too much working capital tied up in excess inventory.
His countermeasure would be to set a key performance indicator (KPI) of inventory levels, or inventory turns, and “hold people accountable” for hitting their targets.
Since there is little interest expressed in how this is done, the savvy numbers-focused subordinate understands the accounting system and sees that inventory levels are taken at the end of each financial quarter, and those levels are used to generate the report of inventory turns. This is also the number used to report to the shareholders and the SEC.
His response is to take actions necessary to get inventory as low as possible during the week or on the day when that snapshot is taken. It is then a simple matter to take actions necessary. A couple of classics are:
Pull forward orders from next quarter, fill and ship them early.
Slow down (or even stop) production in the last week or two of the quarter.
Shift inventory from “finished goods” to “in transit” to get it off the books.
While, in my opinion (which is all that is), actions like this are at best deceptive, and (when reported as true financial results) possibly bordering on fraud, the truth is that these kinds of things happen all of the time in reputable companies.
So what is the countermeasure?
In a “management by measurement” culture, the leader (if he cares in the first place), would respond to put in additional measurements and rules that, hopefully, constrain the behavior he does not want. He would start measuring inventory levels more often, or take an average. He would measure scheduled vs. actual ship dates. He would measure “linearity” of production.
Fundamentally, he would operate on the belief that, if only he could measure the right things, that he would get the performance he needs, in the way it should be done. “The right measurements produce the right results.”
While not universal, it is also very common for a work environment such as this one to:
Attach substantial performance bonuses to “hitting the numbers.”
Confuse this with “empowerment” – and perceive a subordinate who truly wants help to develop a good, sound plan as less capable than one who “just gets it done.” He is seen as “high maintenance.” (“Don’t come to me with problems unless you have a solution.”)
Look for external factors that excuse not hitting the targets. (Such as an increase in commodity prices.)
Take credit for hitting the targets, even when it was caused by external factors. (Such as a drop in commodity prices.)
Overall, there is no real interest in the assessment of why there even is a gap between the current value and the target (why do we need this inventory in the first place?); and there is even less interest in a plan to close the gap, or in understanding if success (or failure) was due to successful execution or just plain luck.
The higher-level leader says he “trusts his people” and as such, is disengaged, uninformed, and worse, is taking no action to develop their capabilities. He has no way to distinguish between the people who “hit the numbers” due to luck and circumstances (or are very skilled at finding external factors to blame) and the ones who apply good thinking, and carry out good plans. Because the negative effects often take time to manifest, this process can actually bias toward someone who can get good short-term results, even at the cost of long-term shareholder value.
This is no way to run a business. A lot of businesses, some of them very reputable, are run exactly this way.
So What’s The Alternative?
Shook describes a patient-yet-relentless leader who is determined to get the results he wants by developing his subordinate. He assigns a challenging task, specifies the approach (the “A3 Problem Solving Process”) then iterates through the learning process – while applying the principle of small steps. At no point does he allow the next step to proceed until the current one is done correctly.
“Do not accept, create, or pass on poor quality.”
He has a standard, and teaches to that standard.
He is skeptical and intently curious – he must be convinced that the current situation is understood.
He must be convinced that the root cause is understood.
He must be convinced that all alternative countermeasures were explored.
He must be convinced that everyone involved has been consulted.
He must be convinced that all necessary countermeasures are deployed – even ones that are unpopular.
He must be convinced that the plan is being tracked during execution, results are checked against expectations, and additional countermeasures are applied to handle any gaps.
And he must be convinced that the results came as an outcome of specific actions taken, not just luck.
In short, even though he might have been able to do it quicker by just telling his subordinate what to do, in the end, that Team Member would only know his boss’s opinion on a particular solution for a specific issue… he would not have taught how to be thorough.
The Learning Countermeasure
If we start in the same place – too much inventory, too few turns – the engaged leader starts the same way, by setting a target.
Then he asks each of his subordinates to come back to him with their plan.
By definition that plan includes details of their understanding of the situation – where the inventory is, why it is. It includes targets – where the effort will be focused, and what results are expected.
The plan includes detailed understanding of the problems (causes) which must be addressed so that the system can operate in a sustainable, stable way, at the reduced inventory levels.
It includes the actions which will be taken – who will do what by when, and the results expected from those actions. It may include other actions considered, but not taken, and why.
It includes a process to track actions, verify results, and apply additional countermeasures when there is a barrier to execution or a gap in the outcome.
The process of making the plan would largely follow the outline in Managing to Learn. The engaged leader is going to challenge the thinking at each step of the process. He is going to push until he is convinced that the Team Member has thoroughly understood – and verified – the current situation, and that the actions will close the gap to the targets.
Rather than assigning a blanket reduction target, the engaged leader might start there, but would allow the Team Members to play off each other in a form of “cap and trade.” The leader’s target needs to get hit, but different sectors may have different challenges. Blanket goals rarely are appropriate as anything but a starting point. But it is only after everyone understands their situation, and works as a team, that they could come up with a system solution that would work.
Of course then the Team Members who had to take on less ambitious targets would get that much more attention and challenge – thus pushing the team to ever higher performance.
Today’s World
Even in companies deploying “lean”, the quality of the deployment is dependent on the person in charge of that piece of the operation. When someone else rotates in, the new leader imposes his vision of how things should be done, and everything changes.
There are, in my view, two nearly universal points of failure here.
The company leadership had an expectation to “get lean” but, above that local level, really had no idea what it means… except in terms of performance metrics. This is often wrapped in a facade of “management support.” Thus, there is no expectation that an incoming leader do things in any particular way. (What is yourprocess to “on board” a new leader prior to just turning him loose with your profits and losses?)
The outgoing leader may have done the right things in the wrong way – by directing what was to be done vs. guiding people through the process of true understanding.
Fixing this requires the same thinking and the same process as addressing any other problem. Just trying to impose a standard on things like production boards isn’t going to work. The issue is in the thinking, not in the tools.
Conclusion
You get what you measure, but don’t be surprised if people are ingenious in destructive ways in how they get there.
You can’t force a solution by adding even more metrics.
Only by knowing what you did (the process) will you know why you got the results you achieved (or did not achieve). This is a process of prediction, and is the only way people learn.
Learning takes practice. Practice requires humility and a mentor or teacher who can see and correct.
Managing to Learnby John Shook is the latest in the classic series of books published by the Lean Enterprise Institute.
It is subtitled “Using the A3 management process to solve problems, gain agreement, mentor, and lead” and that pretty well sums it up.
Like many of the previous LEI books, it is built around a straightforward working example as a vehicle to demonstrate the basic principles. As such, it shares all of the strengths and shortcomings of its predecessors.
In my admittedly limited experience, I have seen a couple of companies try to embrace similar processes without real success. The main issue has been that the process quickly became “filling out a form.” Soon the form itself became (if you will pardon the term) a pro-forma exercise. Leadership did not directly engage in the process; and no one challenged a shortcut, jumping to a pet solution, or verified actual results (much less predicted them). Frankly, in these cases, it was either taught badly from the beginning, or (probably worse) the fad spread more quickly than the organization could learn how to do it well.
I must admit that with the recent flood of books and articles about the “A3” as the management and problem solving tool of lean, that we will see a macro- case of the same though throughout industry.
Managing to Learn tries to address this by devoting most of its emphasis on how the leader teaches by guiding and mentoring a team member through the problem solving process. The reader learns the process by following along with this experience, vs. just being told what to put in each block of the paper.
To illustrate this in action, the narrative is written in two tracks. One column describes the story from the problem solver’s viewpoint as he is guided through the process. He jumps to a conclusion, is pulled away from it, and gently but firmly directed through the process of truly understanding the situation; the underlying causes; developing possible countermeasures and implementing them.
Running parallel to that is another column which describes the thoughts of his teacher / manager.
Personally, found this difficult to follow and would prefer a linear narrative. I am perfectly fine with text that intersperses the thoughts and viewpoints of the characters with the shared actions. But given this alternative choice of format, I would have found it a lot easier to track if there had been clear synchronization points between the two story lines. I found myself flipping back and forth between pages, where sentences break from one page to the next in one column, but not the other, and it was difficult to tell at what point I was losing pace with the other column.
To be clear, Shook says in the introduction that the reader can read both at once (as I attempted to do), read one, then the other, or any other way that works. I tried, without personal success, to turn it into a linear narrative by reading a bit of one, then the other.
The presentation format not withstanding, Shook drives home a few crucially important points about this process.
It is not about filling out the form. It is a thought process. Trying to impose a structured form inevitably drives people’s focus toward filling out the form “correctly” rather than solving the problem with good thinking.
He emphasizes the leadership aspect of true problem solving. The leader / teacher may even have a good idea what the problem and solution are, but does not simply direct actions. Instead, the leader guides his team member through the process of discovering the situation for himself. This gets the problem solved, but also develops the people in the organization.
There are also a few real gems buried in the text – a few words, or a phrase in a paragraph on a page – that deserve to have attention called out to them. I am going to address those in separate posts over the next few days.
In the end this book can provide a glimpse of a future state for leadership in a true learning and problem solving culture. But if I were asked if the message is driven home in a way that passes the “sticky test” then I have to say, no. I wish it did, we need this kind of thinking throughout industry and the public and government sectors.
Thus, while this book is very worthwhile reading for the engaged practitioner to add to his insight and skill set, it is not a book I would give someone who was not otherwise enlightened and expect that he would have a major shift in his approach as a result of reading it.
The bottom line: If you are reading this in my site, you will probably find this book worthwhile, but don’t expect that having everyone read it will cause a change in the way your organization thinks and learns.
More than a few organizations I know are starting to understand the importance of establishing a culture of problem solving. Hopefully they are shifting from a tools implementation model to one which emphasizes how people respond to the daily friction generators.
In an email on the topic to a friend today, I cited four things that I think need to be there before this can be achieved. Upon reflection, I’d like to expand upon and share them. I think I can say that a lot of the failures I have seen can be traced back to only emphasizing one or two of them.
The organization must reset its definition of “a problem.”
In “traditional” organizations something is labeled “a problem” when it causes enough disruption (or annoys the right (wrong?) person). Anything that does not cross that threshold is tolerated. The “problem” with this approach is that many small issues are ignored and worked around. Their effects, though, tend to clump and cluster into larger cumulative symptoms. When those symptoms reach the threshold of pain, someone starts wanting some kind of action, but by now it is too late for simple solutions.
Another face of the same thinking is the “big problem” syndrome. “We can’t fix everything.” “We have to prioritize on the big hitters.” True enough, but it is not necessary to fix everything at once. That’s the point. Sure, prioritize the technically tough problems. But, at the same time, put the systems into place that allow everyone to work on the little ones, every day.
When the “big problem” statements are used as a “can’t do it” or “we can never be perfect” excuse, the organization’s underlying mindset has dropped into the ”
The “Chatter as Signal” attitude really means instead of putting together plans and processes and then tossing them over a wall for blind execution, the problem solving organization systematically and continuously checks “reality” (what really happens) against their “theory” (the plan, what they expect to happen). Whenever there is a difference between the two, they look at that as “a problem.”
Maybe the term “problem” is unfortunate.
A lot is made out there about being truly forward-looking organizations seeing “mistakes” as opportunities to learn. A “mistake” is nothing other than an instance of “We did this thinking some specific thing would happen, but something unexpected happened instead.” Or “We thought we could do it this way, but it turns out we couldn’t.” In different words, those events are “the outcome wasn’t what we planned” and “we couldn’t execute the process as planned.” In other words, “problems.”
In summary, specify what you intend to accomplish, how and when you intend to do it.
Any departure, necessary or inadvertent, from this specification is a problem.
The organization must have a process for immediately detecting and responding to problems.
It doesn’t do much good to define a problem unless you intend to respond. And you can’t stand and watch every second for problems to occur. That is the whole point of jidoka. When Sakichi Toyoda developed his loom, the prevailing common thinking was “sometimes the threads break.” “When that happens, some material is ruined.” “That is reality.” “Perfection is impossible.” Chatter is noise.
But Sakichi changed the dynamic when he designed a loom that detected a broken thread and shut itself down before any bad material was woven. Now I am fairly certain that, even today, threads break on weaving equipment. (And the same technology developed by Sakichi is used to detect it.) So, as a jidoka, this is a case of detecting a small problem and containing it immediately so it can be corrected.
Consider this: If the organization really understands jidoka then any problem that goes undetected is a problem. Thus, it isn’t necessary to fix it all at once. Rather, when problems occur, get back to where they occured. Look at the actual situation. What was the very first detectable departure from the intended process? It is quite likely that it is a small thing, and also likely it happens all the time. But this time it didn’t get caught and corrected.
Then ask: Can you prevent this departure from process?
If you can’t, can it be immediately and automatically corrected?
If not, can the process be stopped?
But detecting the problem is only the first step. The response is even more important. When a Team Member (or a machine) detects a problem and calls for help, a real live human needs to show up and show genuine interest. The immediate issue is simple: Fix the problem. Restore a safe operation that produces defect-free output. That may take a temporary countermeasure involving some improvisation, and may compromise speed and cost a little, but safety and quality are never compromised for anything… right?
The next step is to start the process of actually solving the problem. At a minimum, it needs to be written down and put into the “We’ll work on that” management queue (See the next item) to get solved. Note that “fixing it” and “solving it” are two completely separate things.
The organization must have a process for managing problem solving.
When a problem occurs, the first response is to detect it, then to fix (or contain) it. That is jidoka. But at some point, someone has to investigate why it happened, get to the root cause, and establish a robust countermeasure.
However it is done, however, the organizations that do it well:
Have a public written record of what problems are on the radar. The most common approach is a board of some kind in the area where the daily review takes place.
Did I just say “Daily Review?” There is a process to check the status of ongoing problem solving activity every day. Problems being worked on do not get a chance to fall off the radar.
They manage their talent. The organization I talked about in the “Part Shortages” story had a lot of problems, not just in part shortages, but technical issues as well. Initially they had been assigning each problem to someone as soon as it came up. That quickly became unworkable because, in spite of their tremendous talent, the key players really couldn’t focus on more than one or two things at a time. It was demoralizing for them to get hammered at the meetings for “doing nothing” on five problems because they had been working on the other two. The countermeasure was a prioritized pull system. Each new problem went into a queue. As a problem solver became available (because s/he was done with one), the next problem on the list was assigned. The prioritization system was simple: The manufacturing manager could re-sequence the queue at any time.Thus, the problem at the top of the list — the next one to be assigned — was always the next most important. But it was another important rule that made this work. No one could be pulled off a problem s/he was already working on in favor of a “hot” problem. The only exceptions were a safety issue or a defect that had escaped the factory and had been reported by a customer. However you manage it, keep these things in mind:
Don’t arbitrarily multi-task your talent. People can’t multi-task. This is actually overloading. The other word for it is muri.
Don’t jerk them from one thing to the next without allowing them completion.
They solve the problem at the lowest level of the organization capable of solving it. The corollary here is largely covered below, but it bears mentioning here: If the level that should be solving it isn’t capable then they work THAT problem – developing the skill – rather than ignoring the issue or overloading someone who is never going to have the time to work on it. This is probably the most important lesson in this piece.
They deliberately and systematically develop their problem solving skills at all levels.
It is easy to fall into the trap of assuming that someone with a technical degree is a skilled problem solver and critical thinker. Experience suggests otherwise. And even if there are a couple of people who just have the innate talent, there are not enough of them to go around. There are lots of approaches out there. In reality, all of the effective ones are anchored in the same thinking, they just use different tools and lingo to frame that thinking. My best advice is pick one, teach everyone to use it, then insist that they follow the process exactly. Only by doing that will you actually learn if the process itself has weakness or shortcomings.
Along with this is don’t confuse the tools with the process itself. THIS IS CRITICAL: Anything you draw on paper (or create in a computer) is a tool. The seven problem solving tools are not a process. A statistical control chart is not a process. An A3 is not a process. A cloud diagram is not a process. All of these are tools. The framework in which they are used is structured thinking, and that is a process.
This is important because the process itself is straight forward and simple. It can be taught to anyone. Teaching them the tools, however, teaches them nothing at all about how to solve problems. So many “problem solving courses” spend a week teaching people how to build Pareto charts, histograms, tree diagrams, run charts, even build control charts, and yet teach nothing at all about how to solve problems. Most problems can be solved by unsophisticated troubleshooting techniques that systematically eliminate possible causes. Some can’t, but most can.
This got long, but I guess I had a lot to say on the topic. In the background, I am planning on putting together some basic material on “the process of problem solving” and making it available. Hopefully that will help.
As always, comments are encouraged and appreciated. It tells me that someone actually reads this stuff.

 Managing to Learn
Managing to Learn