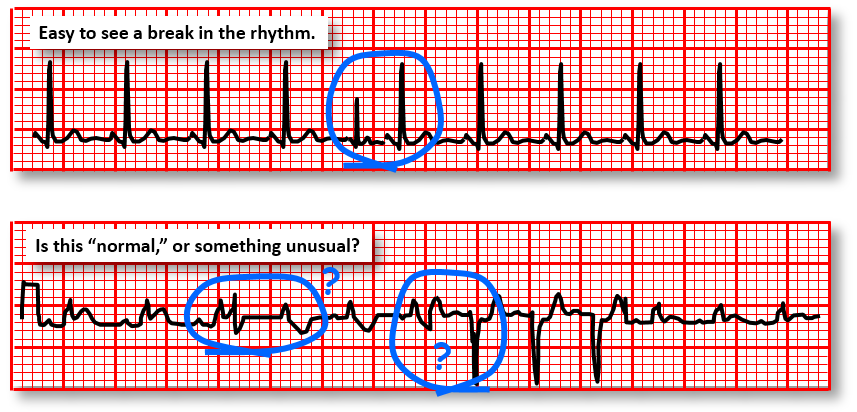
There has been an interesting discussion thread on “Kaizen (Continuous Improvement) Experts” group on LinkedIn over the last few weeks on the differences between takt time and cycle time.
This is one of the fundamentals I’d have thought was well understood out there, along with some nuances, but I was quite surprised by the number (and “quality”) of misconceptions posted by people with “lean” and “Sigma” in their job titles.
I see two fundamental sources of confusion, and I would like to clarify each here.
“Cycle Time” has multiple definitions.
“Cycle time” can mean the total elapsed time between when a customer places an order and when he receives it. This definition can be used externally, or with internal customers. This definition actually pre-dates most of the English publications about the Toyota Production System.
It can also express the dock-to-dock flow time of the entire process, or some other linear segment of the flow. The value stream mapping in Learning to See calls this “production lead time” but some people call the same thing “cycle time.”
In early publications about the TPS, such as Suzaki’s New Manufacturing Challange and Hirano’s JIT Implementation Manual, the term “cycle time” is used to represent what, today, we call “takt time.” Just to confuse things more, “cycle time” is also used to represent the actual work cycle which may, or may not, be balanced to the takt time.
We also have machine cycle time, which is the start-to-start time of a machine and is used to balance to a manual work cycle and, in conjunction with the batch size, is a measure of its theoretical capacity.
“Cycle time” is used to express the total manual work involved in a process, or part of a process.
And, of course, “cycle time” is used to express the work cycle of a single person, not including end-of-cycle wait time.
None of these definitions is wrong. The source of confusion is when the users have not first been clear on their context. Therefore, it is critically important to establish context when you are talking. Adjectives like “operator cycle time” help. But the main thing is to be conscious that this can be a major source of confusion until you are certain you and the other person are on the same wavelength.
Takt time is often over simplified.
The classic calculation for takt time is:
Available Minutes for Production / Required Units of Production = Takt Time
This is exactly right. But people tend to get wrapped up around what constitutes “available time.” The “pure” definition is usually to take the total shift time(s) and subtract breaks, meetings, and other administrative non-working time. Nobody ever has a problem with this. (Maybe because that is the way Shingijutsu teaches it, and people tend to accept what Shingijutsu says at face value.)
So let’s review and example of what we have really done here. For the sake of a simple discussion, let’s assume a single 8 hour shift on a 5 day work week. There is a 1/2 hour unpaid lunch break in the middle of the day, so the workers are actually in the plant “at work” for 8 1/2 hours. (this is typical in the USA, if you are in another country, it might be different for you)
So we start with 8 hours:
8 hours x 60 minutes = 480 total minutes
But there is a 10 minute start-up process in the morning, two 10 minute breaks during the day, and 15 minutes shut-down and clean up at the end of the shift for a total of 45 minutes. This time is not production time, so it is subtracted from “available minutes”:
480 – 45 = 435
A very common mistake at this point would be to subtract the 30 minute lunch break. But notice that we did not include that time to start with. Subtracting it again would count it twice.
So when determining takt time, we would use 435 minutes as the baseline. If leveled customer demand was 50 units / day, then the takt time would be:
435 available minutes / 50 required units of production = 8.7 minutes (or 522 seconds)
Note that you can just as easily do this for a week, rather than a day.
435 minutes x 5 days = 2175 total available minutes
2175 available minutes / 250 required units of production still equals 8.7 minutes (or 522 seconds)
All of this is very basic stuff, and I would get few arguments up to this point, so why did I go through it?
Because if you were to run this factory at a 522 second takt time, you will come up short of your production targets. You will have to work overtime to make up the difference, or simply choose not to make it up.
Why? Because there are always problems, and problems disrupt production. Those disruptions come at the expense of the 435 minutes, and you end up with less production time than you calculated.
Then there is the fact that the plant manager called an all-hands safety meeting on Thursday. That pulled 30 minutes out of your production time. Almost four units of production lost there.
I could go on with a myriad of examples gathered from real production floors, but you get the idea.
Here is what is even worse, though.
When are you going to work on improvements?
If you expect operators to do their daily machine checks, when do you expect that to happen?
Do you truly expect your team members to “stop the line” when there is a problem?
All of these things take time away from production.
The consequence is that the shop floor leadership – the ones who have to deal with the consequences of disrupted production – will look at takt time as a nice theory, or a way to express a quota, but on a minute-by-minute level, it is pretty useless for actually pacing production.
All because it was oversimplified.
If you expect people to do something other than produce all day, you have to give them time to do it.
Let’s get back to the fundamental purpose of takt time and then see what makes sense.
The Purpose of Takt Time
Here is some heresy: Running to takt time is wholly unnecessary. Many factories operate just fine without even knowing what it is.
What those factories lose, however, is a fine-grained sense of how things are going minute by minute. Truthfully, if they have another way to immediately see disruptions, act to clear them, followed by solving the underlying problem then they are as “lean” as anyone. So here is the second heresy: You don’t NEED takt time to “be lean.”
What you need is some way to determine the minimum resource necessary to get the job done (JIT), and a way to continuously compare what is actually happening vs. what should be happening, and then a process to immediately act on any difference (jidoka). This is what makes “lean” happen.
Takt time is just a tool for doing this. It is, however, a very effective tool. It is so effective, in fact, that it is largely considered a necessary fundamental. Honestly, in day to day conversation, that is how I look at it. I made the above statements to get you to think outside the mantras for a minute.
What is takt time, really?
Takt time is an expression of your customer demand normalized and leveled over the time you choose to produce. It is not, and never has been, a pure customer demand signal. Customers do not order the same quantity every day. They do not stop ordering during your breaks, or when your shift is over. What takt time does, however, is make customer demand appear level across your working day.
This has several benefits.
First, is it makes capacity calculations really easy through a complex flow. You can easily determine what each and every process must be capable of. You can determine the necessary speeds of machines and other capital equipment. You determine minimum batch sizes when there are changeovers involved. You can look at any process and quickly determine the optimum number of people required to make it work, plus see opportunities where a little bit of kaizen will make a big difference in productivity.
More importantly, though, takt time gives your team members a way to know exactly what “success” looks like for each and every unit of production. (assuming you give them a way to compare every work cycle against the takt time – you do that, don’t you?)
This gives your team members the ability to let you know immediately if something is threatening required output. Put another way, it gives your entire team the ability to see quickly spot problems and respond to them before little issues accumulate into working on Saturday.
The key point here is that to get the benefit, you have to have a takt time that actually paces production. It has to be real, tangible, and practically applied on the shop floor. Otherwise it is just an abstract, theoretical number.
This means holding back “available time” for various planned (and unplanned) events where production would be stopped.
Further, in a complex flow, there may be local takt times – for example, a process that feeds more than one main line is going to be running to the aggregated demand, and so its takt will be faster than either of them. Likewise, a feeder line that builds up a part or option that is not used on every unit is going to be running slower.
And finally if disruptions do cause shortfalls to the required output, you have to make it up sometime. If you are constrained from running overtime (and many operations are for various reasons), then your only alternative is to build a slight over speed into your takt time calculation. The nuances of this are the topic of a much longer essay, but the basics are this:
– If everything goes well, you will finish early. Stop and use the time for organized improvement of either process or developing people. Continuing to produce is overproduction, and just means you run out of work sooner if you have a good day tomorrow.
– If there are issues, the use the buffer time for its intended purpose.
– If there are more issues than buffer time, there is an operational decision to make. Have a policy in place for this. The simplest is “hope for a better day tomorrow” and use tomorrow’s buffer time to close the gap. If this isn’t enough, then a management decision about overtime or some other remedy is required.
What about just allowing production to fall short? Well.. if this is OK, then you were running faster than customer demand already. So pull that “extra” out of your schedule, stop overproducing (which injects its own disruptions into things), and deal with what just actually have to accomplish. Stop inflating the numbers because they hide the problems, the problems accumulate, and you end up having to inflate even more.
Gee, all of this seems complicated.
Yeah, it can be. But that complexity is usually the result of having an ad-hoc culture that makes up the reactions as you go along rather than a comprehensive thought-out systems-level approach. The key is to work through the “what if…” for what you are doing and thinking about doing, how the pieces actually interconnect and interact, and have a plan.
That plan is the first part of Plan-Do-Check-Act.
Then, as the real world intrudes, you can test your thinking against reality and get better and better rather than just being glad you survived another day.
And that, is the whole point of knowing your cycle times and takt times.