Travel plans sometimes come together at the last minute. I went to the green company’s web site to rent a car, and got a message saying the site was down for maintenance.
It said to please call the 800 number if I wanted to make a reservation.
I called the number.
The nice person on the phone asked if I wanted to make a new reservation or discuss a current one.
I said new reservation.
“Oh, our system is down for maintenance. Can you try again in a few hours?”
It was already midnight, so I really didn’t want to do that.
“That’s OK, I’ll just call Hertz.”
Which I did.
I encountered two problems here.
First was the message that implied that a human could make a reservation while the system was down. The accurate message would have been “Our system is down for maintenance. If you want to make a reservation, please try again in a few hours.”
And, since this is the de-facto process, I have to assume that the company is doing it this way on purpose.
Then again…
Do their executives rent cars through the online system? Do they experience what their customers do? Do they see the “we’re closed, please go away” sign that is part of their normal process every Saturday night?
Another company once put me on hold. The system kicked to a local radio station rather than silence. And so I was waiting for a customer service response while listening to Mick Jagger “I don’t get no… sat is fact ion…”
Boeing’s “PTQ” (Put Together Quickly) videos show a time lapse of an airliner in production. They have been producing the for years – certainly since I was working there.
This one, though, shows something a little special.
When I first started working there, the idea of a line stop was unthinkable. The plane moved on time, period. Any unfinished work “traveled” with the plane, along with the associated out-of-sequence tasks and rework involved.
The fact that the 737 is now built on a continuously moving assembly line in Renton is fairly well known.
But what struck me in this PTQ video is that one of the things highlighted in it is a line stop. It happens pretty quickly at about 1:57.
The video is also full of rich visual controls to allow the team to compare the actual flow vs. the intended flow. See many many you can spot.
Today was traveling on behest of a large corporation, so the travel arrangements were made through them. It all went about as routinely as could be expected on the last weekend before Christmas… for me.
Unfortunately the guy I am supposed to meet here had flights going through D.C. that were on a collision trajectory with a snow storm on the east coast today. Flight cancelled.
OK, I need to continue on, then shift my departure out 24 hours – hang around here another day.
Fortunately at the bottom of the itinerary emailed by the corporate travel company is the handy “In case of problems” etc. phone number:
CONTACT xxx TRAVEL 1-800-3xx-xxxx
So I call the number.
A couple of layers of voice menu prompts (including a reminder that airlines are implementing luggage policies, please check your airline’s web site – totally useless information that only delays the response I am trying to get), I end up with the “hold music” being reminded periodically that “Your call is important to us…” etc.
A human comes on the line and I am cheerfully informed that this is not the 800 number I should call. I am reminded that MY reservation was made through the online system (which it was not, I talked to a human being when I made it), and that I need to call “them.” And, kindly, I am forwarded to “them.”
After 20 minutes of hold music, my plane is boarding, so I have to drop the call.
Try again from the seat.
Different initial operator who makes a little more effort to make me wrong for calling the ONLY number that they print on the itinerary they send, otherwise same result. They are closing the cabin door, I have to drop the call.
There actually is a lesson here.
What defines how well a process or system works is not so much the individual components, but the interfaces between them. In this case the “interface,” if you can call it that, is the hapless (and irritated) customer. I am the one who has to integrate various otherwise separate components of this fractured process.
The other story is the reason they were likely so busy today. After all, a major snow storm socked the east coast and caused havoc in the flight schedules that went through there. I am sure there were plenty of people who were impacted, and calling them for assistance re-booking flights, etc. And after all, there really is no way to predict when that will happen so they could be prepared, right? The really cool thing about 21st century communications technology is that you can can not only monitor live weather conditions and radar in real time, if you need to react, “extra people” don’t even need to leave home to be available… they don’t even need to be in the same state or even country. It is possible to plan and prepare for extraordinary mind-boggling never-forget-it customer service, if it is important to you.
In the end, it is about making a conscious decision about the experience you really want your customer to have, and then structuring your processes, deliberately, to deliver that experience – and be sensitive and alert you when they do not. It is not that big a shift from “serving customers” to “customer service,” nor does it cost more in the long haul. “Quality is free” – if you understand how to do it.
This news piece, America’s Best Hospitals: The 2009-10 Honor Roll, originally got my attention because I hoped someone might be actually be paying attention to the things that make a real difference in our national debate about health care.
Unfortunately, it looks like more of the same.
This survey looks at things like technical capability – what kinds of specialty procedures these hospitals can perform, and their general reputation and then ranks them accordingly.
But where are we asking about the basics?
Which hospitals kill or injure the fewest of their patients? What is the rate of post-operative or other opportunistic infection? How about medication errors? These are the things that all hospitals should be “getting right” and yet the evidence is overwhelming that most don’t. Further, nobody seems to be paying attention to it except tort lawyers.
Whether in service delivery (including health care delivery), manufacturing, or any other production environment, your team members are likely having to make lots of decisions under perceived time pressure. Even with great visual aids, many of these processes are mistake-prone.
One of the reasons I like pre-kitting parts for a specific option configuration is that it separates the process of deciding which parts to pick from the process of installing them.
This might not seem that big a deal.
Fortunately, if you have a copy of Windows Vista, it comes with a great simulation that shows just how this can feel on the line.
Look under “Games” and start the “Purple Place” game. Select the building in the middle of the screen, and you will find yourself in a cake factory.
The idea is to look at the TV monitor on the left, and produce a cake that matches the picture. You can move the belt forward and back to position the cake under the various applicators. Then you simply select the correct choice. Seems pretty simple.
Go ahead, try it.
This screen shot is from the “Advanced” level, but even the “Beginner” is pretty easy to screw up unless you are focused and paying attention all of the time.
So – if you find yourself saying “All the employees need to do is look at the picture, and follow the directions – why is that so difficult?” then see how well you do on this game. Play it from the start of your regular work shift until the first break, say two hours, and see how many mistakes you make.
Now consider that your production environment is likely orders of magnitude more complex than this game for little kids. And you are expecting people to work all day, every day, without ever making a mistake.
If you are in health care delivery – think about the picture of the finished cake as the physician’s instructions, and the production line as the actual process of filling the prescriptions, administering medications, protocols for preventing infections, record keeping procedures, and ask yourself if there aren’t many more opportunities for error – that are far better concealed – than the ones in this little game.
Just a thought for the day. Meanwhile – enjoy finding a work-related reason to have “Games” loaded onto your Vista machine! 🙂
My main desktop computer runs Ubuntu Linux. The default email client is called Evolution. A recent upgrade introduced a very cool feature. When I hit “Send” it looks for language in the email that might indicate I meant to include an attachment. If there is no attachment, it pops up this handy reminder:
Maybe Microsoft Outlook does this too, I haven’t used the latest version, so I don’t know. But in any case, this is a great example of catching a likely error before it escapes the current process. I can’t count the number of times I have hit “Send” only to get an email reply “You didn’t include the attachment.” Obviously I was about to do it again, or I wouldn’t be writing this. 😉 Since I am sending out things like resumes right now, that is something I would really like to avoid.
When talking about mistake proofing, or poka-yoke, there are really three levels.
The first level prevents the error from happening in the first place. It forces correct execution of the correct steps in the correct order, the correct way. While ideal, it is sometimes easier said than done.
The next level detects an error as it is being made and immediately stops the process (and alerts the operator) before a defect is actually produced. That is the case here.
The third level detects a defect after it has occured, and stops the process so that the situation can be corrected before any more can be made.
Each has its place, and in a thorough implementation, it is common to find all of them in combination.
Related to this are process controls.
Each process has conditions which must exist for it to succeed. Having some way to verify those conditions exist prior to starting is a form of mistake-proofing. Let’s say, for example, that your torque guns rely on having a minimum air pressure to work correctly. Putting a sensor on the air line that shuts off the gun if the pressure drops below the threshold would be a form of stopping the process before a defect is actually produced.
A less robust version would sound an alarm, and leave it to the operator to correctly interpret the signal and stop the process himself. Your car does this if you start the engine without having the seatbelt fastened. (back around 1974-75 the engine would not start (see above), but too many people (i.e. Members of Congress) found this annoying so the regulation was repealed.)
Consider the question “Do I have all of the parts and tools I need?” What is the commonly applied method to ensure, at a glance, that the answer to this question is “Yes?”
If you answered “5S” then Ding! You’re right. That is one purpose of 5S.
A common question is how mistake-proofing relates to jidoka.
My answer is that they are intertwined. Jidoka calls for stopping the process and responding to a problem. Inherent in this is a mechanism to detect the problem in the first place.
The “respond” part includes two discrete steps:
Fixing or correcting the immediate issue.
Investigating, finding the root cause, and preventing recurrance.
Thus, the line stop can be initiated by a mistake-proofing mechanism (or by a person who was alerted by one), and mistake-proofing can be part of the countermeasure.
But it is not necessary to have mistake proofing to apply jidoka. It is only necessary for people to understand that they must initiate the problem correction and solving process (escalate the problem) whenever something unprogrammed happens. But mistake-proofing makes this a lot easier. First, people don’t have to be vigilant and catch everything themselves. But perhaps more importantly, they don’t have to take the (perceived) psychological risk of calling out a “problem.” The mechanics do that for them. It is safer for them to say “the machine stopped” than to say “I stopped the machine.”
Tom posed an interesting question on The Whiteboard.
Has anybody else noticed that quality is taking a back seat lately due to the tough economic conditions? Things are tough everywhere, but I’m seeing more and more evidence of companies taking short cuts (to cut costs) where the end result is poor quality.
I’ll say what I think, but I would also like to invite anyone else to comment as well. This is an important issue.
Background:
First, it is important to understand that the term “quality” carries at least three definitions. There may be more, but here is how I came to understand them.
Grade: The product’s position in the market.
Fitness for use: Whether the product is suitable for the customer’s intended purpose.
Conformance to specification: Whether the product is as the producer intended it.
Some examples.
Grade:
In air travel, there are two (and sometimes three) grades of service offered on a typical flight. Coach is basic transportation. It gets you there quickly and safely. First Class gets you there just as quickly and just as safely as coach. But there are more amenities offered, the seats are bigger, in general it is more comfortable. First Class is a higher grade of product.
In the automobile market, we have expensive luxury cars, such as top-end BMW or Lexus. We have middle grade cars, we have basic cars. Even within a specific make and model, there are different trim levels that each carry a different “feel” as well as a different price.
Thus, the grade of the product reflects an effort to create higher value by adding features and amenities that probably go above and beyond the basic purpose.
It is important to understand that the grade of the product is set by the producer’s decisions on market position. They are trying to deliver more value in order to command higher prices.
Fitness for Use:
Fitness for use is defined from the perspective of the customer. The product is sold as being suitable for some purpose, and the customer buys it to fill a need. How well it fills that need is ultimately defined by the customer’s experience of the product in use. This is probably the easiest to screw up, as many companies tend to rely on internal experts or the highest-paid-person’s opinion rather than getting their shoes dirty and actually paying attention to what customers do with the product. It is easy to delete or alter a feature which turns out to be very important to the customer. Customers can also surprise you and find uses which were never intended by the original design.
Conformance to Specification:
Once the research is done, and the product designed, some kind of production system must be established to actually produce the product (or actually deliver the service, it is the same issue). Conformance to specification defines how well the product delivery actually matches the design intent. Where a Hilton Hotel may offer a higher grade of room than Motel 6, if both rooms are clean, ready for guests, and meet their respective hotel’s standards, then both conform to specification. The Hilton will have some kind of specification for how they deliver room service. Motel 6 has a Denny’s next door.
One More Example
If I am interested in knowing what time it is, a $35 Timex will do exactly the same job as a $5000 Rolex. With today’s quartz technology, they are both accurate within a second or two per month. So if knowing the time is my intended use, both watches are fit for use.
Clearly, however, there is a difference. The Rolex is a higher grade of product than the Timex. If my purpose is to demonstrate wealth or success, or present an extravagant gift, the Rolex is also more fit for that use.
But if they each work out of the box exactly as intended, have no scratches or other defects, then both watches conform to the specifications of their respective manufacturers. Both companies have excellent reputations for “quality” in that sense.
So now to Tom’s question.
Companies facing dramatically declining sales are under great cost pressure. Very few have limitless sources of cash to burn, and publicly held companies must also maintain the goodwill of their investors. In addition, many companies have credit covenants which require them to maintain certain ratios of debt, liabilities, assets, liquidity, etc, or face issues with their banks.
With that background, let’s look at how these pressures could drive decisions that affect quality.
Deliberate decisions are most likely to affect grade. Cheaper materials may be substituted, amenities or extra services can be cut back. Anyone who flys frequently has seen the steady erosion in previously “free” services and amenities as airlines come under increasing cost pressure. The danger here, of course, is that these decisions also reduce value in the eye of the customer, and with that, can reduce the price they are willing to pay or send them to a competitor. Thus, these “savings” can end up backfiring unless the entire industry is following pretty much the same path.
I think the more dangerous effect of turbulent times, however, is in the area of conformance to specification. But I don’t think this is the result of deliberate shortcuts. Rather, I think it is an unintended consequence at the intersection of a couple of other factors.
First, relatively few companies, be they production and manufacturing or service delivery, have an effective system of assuring that things are done the way they expect. When times are good, and employment is stable, the people develop their own individual feel for what is right and do their very best to do it. The level of quality will reach some kind of tolerable norm which may, or may not, conform to the specification.
Now mix things up. Lay off some of your workers, and move the others around. Different people are doing different jobs. Because the work is not well specified in the first place, and because there is likely no process to transfer “how to do it” (like TWI Job Instruction), people have to learn the hard way – by making mistakes. Add to the mix a perceived time pressure, and people will take shortcuts in a good faith effort to get the job done the way they think they are expected to.
If the “specification” itself is poorly defined as well, then the new “norm” for the organization could very well end up different (and worse) than what it was before. Add to that a management culture of acceptance of “what is, is” (an excused-based culture, more common than you think, especially in large companies), and you get a seeming erosion.
So here’s what I think – if Tom is seeing an erosion of quality, he is likely seeing the effect of the economic turmoil rather than deliberate decisions to cut corners. Further, is impossible to deliberately cut corners if no one has ever defined where the corners are in the first place. And that situation is more normal than not.
Before I go any further, I have to say that I have spent loads of time in China. I have very close Chinese friends. The Chinese are like everyone else in the world – hard working honorable people. But, just like everywhere else in the world, now and then someone takes shortcuts with known technology, or doesn’t understand the “Why?” behind industry standard practices, and rarely, there is a real crook.
The great question, though, is “To what degree are the importers, builders and contractors culpable, and to whom?”
The U.S. arm of the Chinese company is swearing up and down that their product meets U.S. standards. Pretty standard rhetoric for muddling the issue.
I don’t even want to get into the legal issues here. They are going to be very messy.
But if you bought a car, and it turned out that the imported, outsourced seats were emitting noxious fumes, I doubt you would turn to the seat manufacturer to resolve the problem.
OEM’s? Know your suppliers, know your supply chain.
Unfortunately we will end up with a ton more government regulation as a result of industry being unable or unwilling to assure its own quality, and that is going to cost all of us.
Kind of makes the term “toxic assets” more real, doesn’t it?
In past posts, I have referred to an organization that implemented a “morning market” as a way to manage their problem solving efforts.
Synchronicity being what it is:
Barb, the driving force in the organization in my original story, wrote to tell me that their morning market is going strong – and remains the centerpiece of their problem solving culture. In 2008, she reports, their morning market drove close to 2000 non-trivial problems to ground. That is about 10/day. How well do you do?
Edited to add in March 2015: I heard from Barb again. It is still a core part of the organization’s culture.
So – to organizations trying to implement “a problem solving culture” and anyone else who is interested, I am going to get into some of the nuts and bolts of what we did there way back in 2003. (I am telling you when so that it sinks in that this is a change that has lasted and fundamentally altered the culture there.)
What is “A Morning Market?”
The term comes from Masaaki Imai’s book Gemba Kaizen pages 114 – 118. It is a short section, and does not give a lot of detail. The idea is to review defects “first thing in the morning when they are fresh” – thus the analogy to the early morning fish and produce markets. (For those who like Japanese jargon, the term is asaichi, but in general, with an English speaking audience, I prefer to use English terms.)
The concept is to display the actual defects, classified by what is known about them.
‘A’ problems: The cause is known. Countermeasures can be implemented immediately.
‘B’ problems: The cause is known, countermeasures are not known.
‘C’ problems: Cause is unknown.
Each morning the new defects are touched, felt, understood. (The actual objects). Then the team organizes to solve the problem. The plant manager should visit all of the morning markets so he can keep tabs on the kinds of problems they are seeing.
Simple, eh?
Putting It Into Practice
Fortunately we were not the pioneers within the company. That honor goes to another part of the company who was more than willing to share what they had learned, but their key lesson was “put two pieces of tape on a table, divide it into thirds, label them A, B and C and just try it.”
They were right – as always, it is impossible to design a perfect process, but it is possible to discover one. Some key points:
There is a meeting, and it is called “the morning market” but the meeting does not get the problems solved. The difference between the organizations that made this work and the ones that didn’t was clear: To make it work it is vital to carve out dedicated time for the problem solvers to work on solving problems. It can’t be a “when you get around to it” thing, it must be purposeful, organized work.
The meeting is not a place to work on solving problems. There is a huge temptation to discuss details, ask questions, try to describe problems, make and take suggestions about what it might be, or what might be tried. It took draconian facilitation to keep this from happening.
The purpose of the meeting is to quickly review the status of what is being worked on, quickly review new problems that have come up, and quickly manage who is working on what for the next 24 hours. That’s it.
The morning market must be an integral part of an escalation process. The purpose is to work on real problems that have actually happened. Work on them as they come up.
Just Getting Started
This was all done in the background of trying to implement a moving assembly line. There is a long back story there, but suffice it to say that the idea of a “line stop” was just coming into play. Everyone knew the principle of stopping the line for problems, but there was no real experience with it. As the line was being developed, there were lots of stops just to determine the work sequence and timing. But now it was in production.
The first point of confusion was the duration of a line stop. Some were under the impression that the line would remain stopped until the root cause of the problem was understood. “No, the line remains stopped until the problem can be contained,” meaning that safe operations that assure quality are in place.
The escalation process evolved, and for the first time in a long time, manufacturing engineers started getting involved in manufacturing.
The actual morning market meeting revolved around a whiteboard. At least at first. When they started, they filled the board with problems in a day or two. They called and said they wanted to start a computer database to track the problems. I told them “get another board.” In a few days that board, too, filled up. It really made sense now to start a computer database. Nope. “Get another board.” That board started to fill.
Then something interesting happened. They started clearing problems.
PDCA – Refining The Process
The tracking board evolved a little bit over time.
The first change was to add a discrete column that called out what immediate measures had been taken to contain the problem and allow safe, quality production to resume. This was important for two reasons.
First, it forced the team to distinguish between the temporary stop-gap measure that was put in immediately and the true root-cause / countermeasure that could, and would, come later. Previously the culture had been that once this initial action were taken, things were good. We deliberately called these “containments” and reserved the word “countermeasure” for the thing that actually addressed root cause. This was just to avoid confusion, there is no dogma about it.
Second, it reminded the team of what (probably wasteful) activity they should be able to remove from the process when / if the countermeasure actually works. This helped keep these temporary fixes from growing roots.
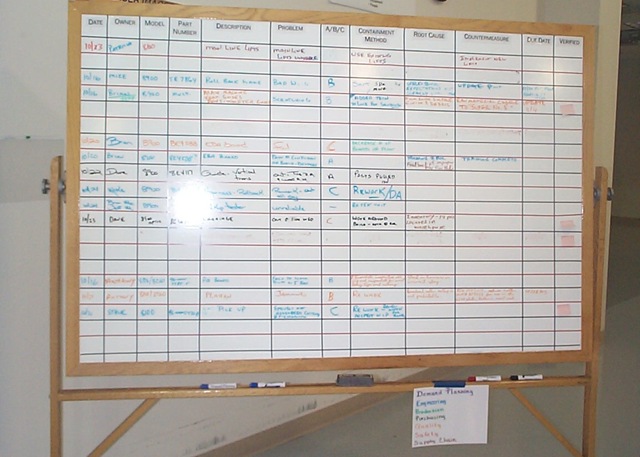
You can get an idea of what a typical problem board looked like here:
The columns were:
Date (initial date the problem was encountered)
Owner
Model (the product)
Part Number (what part was involved)
Description (of the part)
Problem (description of the problem)
A/B/C (which of the above categories the problem was now. Note that it can change as more is learned.
Containment Method
Root Cause (filled in when learned)
Countermeasure (best known being tried right now)
Due Date (when next action is due / reported)
Verified (how was the countermeasure verified as effective?)
A key point is that last column: Verified. The problem stays on the board until there is a verified countermeasure in place. That means they actually tested the countermeasure to make sure it worked. This is, for a lot of organizations, a big, big change. All too many take some action and “call it good.” Fire and forget. This little thing started shifting the culture of the organization toward checking things to make sure they did what they were thought to do.
Refining The Meeting
While this particular shop floor was not excessively loud, it was too loud for an effective meeting of more than 3-4 people. Rather than moving the meeting to a conference room, the team spent $50 at Wally World and bought a karaoke machine. This provided a nice, inexpensive P.A. system. It added the benefit that the microphone became a “talking stick” – it forced people to pay attention to one person at a time.
Developing Capability
The other gap in the process that emerged pretty quickly was the capability of the organization to solve problems. While there had been a Six Sigma program in place for quite a while, most of skill revolved around the kinds of problems that would classify as “black belt projects.” The basic troubleshooting and physical investigation skills were lacking.
After exploring a lot of options, the organization’s countermeasure was to adopt a standard packaged training program, give it to the people involved in working the problems, then expecting that they immediately start using the method. This, again, was a big change over most organization’s approach to training as “interesting.” In this case, the method was not only taught, it was adopted as a standard. That was a big help. A key lesson learned was that, rather than debate which “method” was better, just pick one and go. In the end, they are all pretty much the same, only the vocabulary is different.
Spreading The Concept
In this organization, the two biggest “hitters” every day were supplier part quality and supplier part shortages. This was pretty much a final-assembly and test only operation, so they were pretty vulnerable to supplier issues. This process drove a systematic approach to understand why the received part was defective vs. just replacing it. Eventually they started taking some of their quality assurance tools upstream and teaching them to key suppliers. Questions were asked such as “How can we verify this is a good part before the supplier ships it?” They also started acknowledging design and supplier capability (vs. just price and capacity) issues.
On the materials side, the supply chain people started their own morning market to work on the causes of shortages. I have covered their story here.
As they implemented their kanban system, morning markets sprang up in the warehouse to address their process breakdowns. Another one addressed the pick-and-delivery process that got kits to the line. Lost cards were addressed. Rather than just update a pick cart, there was interest in why they got it wrong in the first place, which ended up addressing bill-of-material issues, which, in turn, made the record more robust.
Managing The Priorities
Of course, at some point, the number of problems encountered can overwhelm the problem solvers. The next evolution replaced the white board with “problem solving strips.” These were strips of paper, a few inches high, the width of the white board, with the same columns on them (plus a little additional administrative information). This format let the team move problems around on the wall, group them, categorize them, and manage them better. Related issues could be grouped together and worked together. Supplier and internal workmanship issues could be grouped on the wall, making a good visual indication of where the issues were.
“Problem Strips” at the meeting.
But those were all side effects. The key was managing the workload.
Any organization has a limited capacity to work on stuff. The previous method of assignment had been that every problem was assigned to someone on the first day it was reviewed. It became clear pretty quickly that the half a dozen people actually doing the work were getting a little sick of being chided for not making any progress on problems 3, 4 and 5 because they were working on 1 and 2. In effect, the organization was leaving the prioritization to the problem solvers, and then second guessing their choices. This is not respectful of people.
The countermeasure – developed by the shop floor production manager, was to put the problems on the strips discussed above. The reason she did it was to be able to maintain an “unassigned” queue.
Any problem which was not being worked on was in the unassigned queue on the wall. All of the problems were captured, all were visible to everyone, but they recognized they couldn’t work on everything at once. As a technical person became available, he would pull the next problem from the queue.
There were two great things about this. First, the production manager could reshuffle the queue anytime she wanted. Thus the next one in line was always the one that she felt was the most important. This could be discussed, but ultimately it was her decision. Second is that the queue became a visual indicator that compared the rate of discovering problems (into the queue) with the rate of solving problems (out of the queue). This was a great “Check” on the capacity and capability of the organization vs. what they needed to do.
There were two, and only two, valid reasons for a problem to bypass this process.
There was a safety issue.
A defect had escaped the factory and resulted in a customer complaint.
In these cases, someone would be assigned to work on it right away. The problem that had been “theirs” was “parked.” This acknowledged the priority, rather than just giving him something else to do and expecting everything else to get done too. (This is respect for people.)
Incorporation of Other Tools
Later on, a quality inspection standard was adopted. Rather than making this something new, it was incorporated into the problem solving process itself. When a defect was found, the first step was to assess the process against the standard for the robustness of countermeasures. Not surprisingly, there was always a pretty significant gap between the level of countermeasures mandated by the standard and what was actually in place. The countermeasure was to bring the process up to the standard.
The standard itself classified a potential defect based on its possible consequences. For each of four levels, it specified how robust countermeasures should be for preventing error, detecting defects, checking the process, secondary checks and overall process review. Because it called out, not only technical countermeasures, but leadership standard work, this process began driving other thinking into the organization.
Effect On Designs
As you might imagine, there were a fair number of issues that traced back to the design itself. While it may have been necessary to live with some of these, there was an active product development cycle ongoing for new models. Some of the design issues managed to get addressed in subsequent designs, making them easier to “get right” in manufacturing.
What Was Left Out
The things that got onto the board generally required a technical professional to work them. These were not trivial problems. In fact, at first, they didn’t even bother with anything that stopped the line for less than 10 minutes (meaning they could rework / repair the problem and ship a good unit). But even though they turned this threshold down over time, there were hundreds of little things that didn’t get on the radar. And they shouldn’t… at least not onto this radar.
The morning market should address the things that are outside the scope of the shop floor work teams to address.
Another organization I know addressed these small problems really well with their organized and directed daily kaizen activity. Every day they captured everything that delayed the work. Five second stoppages were getting on to their radar. Time was dedicated every day at the end of the shift for the Team Members to work on the little things that tripped them up. They had support and resources – leadership that helped them, a work area to try out ideas, tools and materials to make all of the little gadgets that helped them make things better. They didn’t waste their time painting the floor, making things pretty, etc. unless that had been a source of confusion or other cause of delay. Although the engineers did work on problems as well, they did not have the work structure described above.
I would love to see the effect in an organization that does all of this at once.
No A3’s?
With the “A3” as all the rage today, I am sure someone is asking this question while reading this. No. We knew about A3’s, but the “problem solving strips” served about 75% of the purpose. Not everything, but they worked. Would a more formal A3 documentation have worked better? Not sure. This isn’t dogma. It is about applying sound, well thought out methodology, then checking to see if it is working as expected.
Summary
Is all of this stuff in place today? Honestly? I don’t know. [Update: As of the end of 2011, this process is still going strong and is strongly embedded as “the way we do things” in their culture.] And it was far from as perfect as I have described it. BUT organized problem solving made a huge difference in their performance, both tangible and intangible. In spite of huge pressure to source to low-labor areas, they are still in business. When I read “Chasing The Rabbit” I have to say that, in this case, they were almost there.
And finally, an epilogue:
This organization had a sister organization just across an alley – literally a 3 minute walk away. The sister organization was a poster-child for a “management by measurement” culture. The leadermanager person in charge sincerely believed that, if only he could incorporate the right measurements into his manager’s performance reviews, they would work together and do the right things. You can guess the result, but might not guess that this management team described themselves as “dysfunctional.” They tried to put in a “morning market” (as it was actually mandated to have one – something else that doesn’t work, by the way). There were some differences.
In the one that worked, top leaders showed up. They expected functional leaders to show up. The people solving the problems showed up. The meeting was facilitated by the assembly manager or the operations manager. After the meeting people stayed on the shop floor and worked on problems. Calendars were blocked out (which worked because this was a calendar driven culture) for shop floor problem solving. Over time the manufacturing engineers got to know the assemblers pretty well.
In the one that didn’t work, the meeting was facilitated conducted by a quality department staffer. The manufacturing engineers had other priorities because “they weren’t being measured on solving problems.” After the meeting, everyone went back to their desks and resumed what they had been doing.
There were a lot of other issues as well, but the bottom line is that “problem solving” took hold as “the way we do things” in one organization, and was regarded as yet another task in the other.
About 8 months into this, as they were trying, yet again, to get a kanban going, a group of supervisors came across the alley to see what their neighbors were doing. What they saw was not only the mechanics of moving cards and parts, but the process of managing problems. And the result of managing problems was that they saw problems as pointing them to where they needed to gain more understanding rather than problems as excuses. One of the supervisors later came to me, visibly shaken, with the quote “I now realize that these people work together in a fundamentally different way.” And that, in the end, was the result.
In the end? The organization in this story is still in business, still manufacturing things in a “high cost labor” market. The other one was closed down and outsourced in 2005.
Each day you are exposed to an unimaginable number of viruses and bacteria. Any one of them has the potential to overwhelm your body and kill you. But your immune system detects the foreign body, responds, swarms the source of infection, defeats it, and learns so that your immunity is actually strengthened in the process.
Some people, for various reasons, have weak or suppressed immune systems. They suffer from chronic infections. Even if their immune system keeps the infection under control, it is not strong enough to eliminate it. Things which someone else might not even notice take a daily toll on their energy and life.
Your immune system represents your body’s strength to deal with the unanticipated and the unexpected.
In your organization, people encounter unanticipated and unexpected things every day. A small inconsequential defect causes some inconsequential rework. A missing part causes a search and expedite. Each of these things, in turn, propagates more variation, like expanding waves, into the system around it. The variation becomes an infection in your processes, and it has the potential to grow without bounds.
Most organizations have very weak immune systems. They are chronically sick, and expending incredible amounts of time and energy dealing with these “infections.” Because each “infection” is, at best, accommodated rather than eliminated, they tend to accumulate. More and more of the organization’s energy is expended coping.
In the work place this means that the success of the process becomes totally reliant on the vigilance of each individual, working pretty much alone, to see problems and control them enough that some form of output can continue. Worse, many organizations build elaborate systems to assign blame when one of these thousands of opportunities for problems is missed.
Ironically, a lot of “blitz” type kaizen activity actually makes the the system more sensitive to these kinds of problems. If there is no corresponding effort to strengthen the response (swarm, fix, solve) to these problems, it is no wonder that things slide back pretty quickly.
Variation is an infection. And like the viruses and bacteria we are exposed to every day, it will always be there. It is only your ability to quickly detect variation, rapidly contain it, and then deal with its cause that strengthens your organization’s ability to deal with the next one.