This photo says a lot about the organization. For those of you who might not come from an industrial background, the big red button on this podium is the E-Stop – the Emergency Stop button that shuts down EVERYTHING in the machine IMMEDIATELY.
It is there in case someone is about to get hurt (or worse, is getting hurt). It must be accessible fast so you can just smack it with your palm.
But that isn’t the case here. It is a tape holder. And the tape has to be moved to hit the E-Stop.
Walking around this (now long closed) factory, I saw a lot of this kind of functional disorganization. It was normal. It was, by definition, OK because the leadership (at least those who came out to the shop floor) walked past it every day and didn’t say anything.
I wasn’t there to help fix it, they weren’t a client. I did pick up the tape and suggest to the machine operators that they should find a better place to put it, and why. I did that because I cared for their safety. But the workbench covered 7 inches deep in junk? Interesting, but in this case, the Prime Directive was in play for me.
Take a walk through your organization. What do you see? That is your “OK.”
Here’s the model I shared a couple of years ago in a KataCon keynote:
Standards vs. Reality = The Gap
Every organization has a gap between their standards and their reality. What differentiates between high performance and just getting along is the magnitude of that gap.
The gap forms because, left unchecked, all processes begin to erode as soon as they are put into place. As unforeseen issues come up, people left to their own devices will develop work-arounds, add (or omit) steps, and improvise as necessary to do what they believe must be done. They are working hard to do what they believe the organization thinks is important.
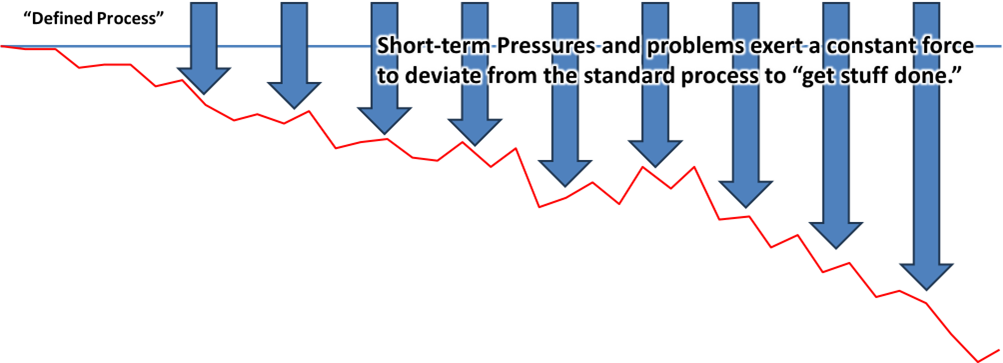
We can think of it like this: The blue line represents the defined or aspirational standard. The arrows represent the constant pressures to “find a way to get it done” and the red line represents the steady separation of reality from the defined process.
This downward trend continues until things are bad enough that someone intervenes.
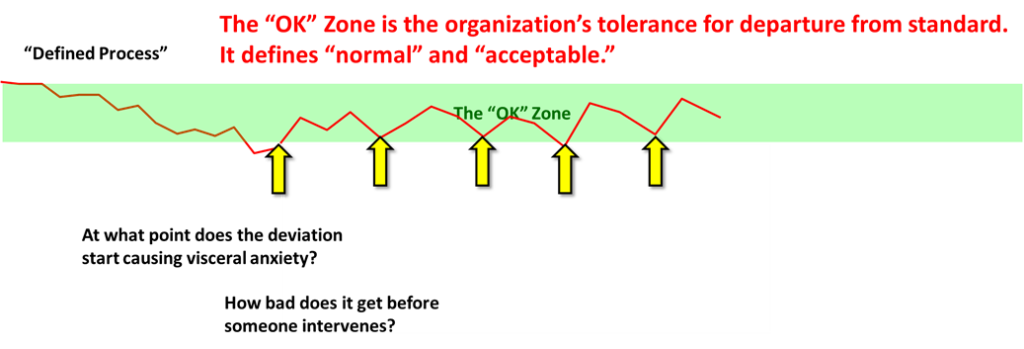
That threshold of intervention exerts upward pressure on the process and maintains it at some level of normal. We have to remember that “normal” means “what we would expect to see.” It doesn’t mean we like normal. It just is.
Anything between the defined process and “normal” and “acceptible” is in your “OK Zone” meaning, “This is OK,” I’m not going to take the time or energy to try to hold it up any higher.
If you want to know what your OK zone looks like, just walk around and look. It is what you see every day.
Unless the intervention threshold changes, any improvements you make will quickly revert to the “OK Zone” baseline.
The question for organizations wishing to up their game and develop a culture of robust execution is: “What would it take to trigger the intervention more quickly, when there is less deviation from the standard?”
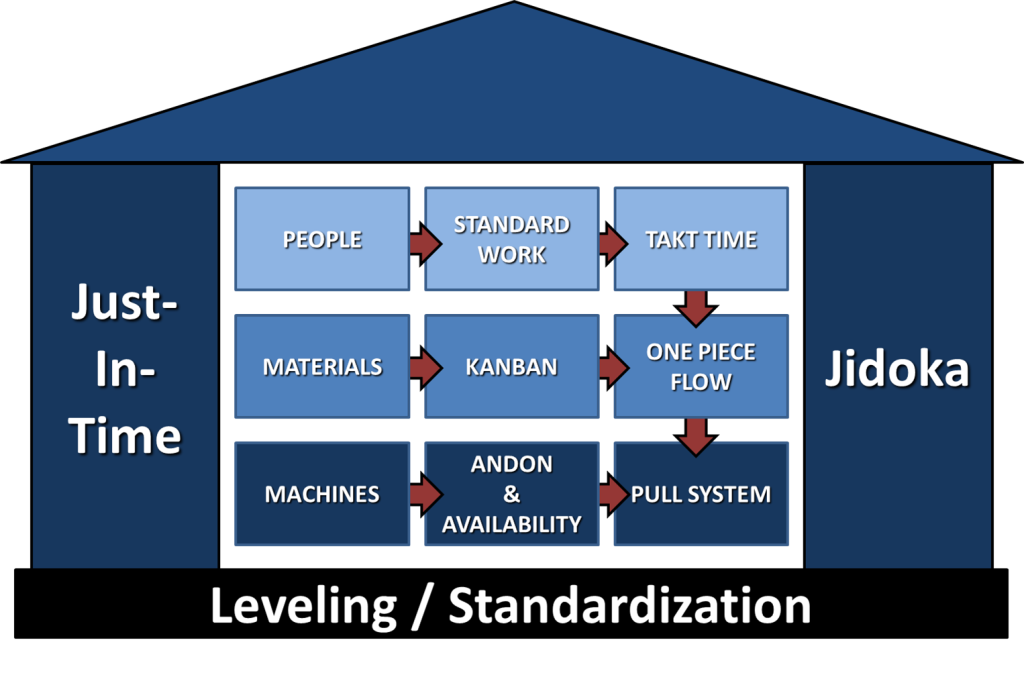
The purpose of ALL of the so-called “lean tools” is to highlight the gap, and invite people to do something about it. None of the lean tools intervene on their own, nor correct a deviation, nor actively improve your process. Only people can do that. The tools enable people by giving them the information they need to quickly know when, and how, to intervene, correct, and seek to understand the problem.
I was working with this company mainly on their shop floor processes: Quality, Process Improvement, Daily Management – classic stuff. It was a medium sized plant (a few hundred people) that was part of a larger company with significant business footprints in Europe and North America.
They hadn’t involved me in their upcoming ERP implementation. Heck, they hadn’t even told me they were switching systems. I just heard about it in the course of the day-to-day conversations. My feeling was they were treating this as background noise in their daily business, and I told them. “Focus on this, it will be one of the hardest things you have ever done, and if you treat it casually it will bite you” (or words to that effect).
I was assured that everything was under control.
Over the ensuing weeks I saw a conference room full of outside people all sitting at laptops. I also saw “training” sessions that were mostly lecture and demonstration of the features of the new software. I picked up on conversations that circled around “How will the new system ___(fill in one of their perceived necessary work tasks)___.”
I wasn’t on site on the day the cut over to the new system – and simultaneously cut off their legacy system.
I was on site during the aftermath.
Work orders were released without materials available.
Shipment manifest errors were causing customer rejections.
There were surprise shortages of basic commodity supplies.
The production planners were really struggling.
Sales revenue dropped. Revenue dropped. The bottom line impact was, to say the least, significant.
Corporate’s response was to assemble a team of experts from the global operations and parachute them into this site to get things working.
The first step was to have each stakeholder (the area managers, such as supply chain) to identify, exactly, what problems they had.
We had them write what they thought the problem was. On the first pass, these were usually things they wanted the system to do. In reality, in most cases it was something they didn’t know how to do, but that is getting ahead of the story. Each of those items was written on a single 5×8 inch index card.
Then we had them write their definition of “Solved” as in, “This problem is solved when ___.” and that had to be something that their Team Members could demonstrate back to the stakeholder / manager. We did it this way to make sure that the stakeholder had a clear criteria that, when met, they would verify that this was no longer a problem for them.
Part of that was to remove ambiguity. Part of it was for the stakeholder to accept accountability for the solution vs. saying later that they were not happy.
We then had the outside experts review the cards and accept the ones they would help with.
Now comes the interesting part.
We established a vertical column on the wall for the work of each outside expert.
The stakeholder / managers now had to get together and agree on the priority order among themselves. The stakeholders controlled the priority. The cards were taped to the wall in priority order, top to bottom.
What we had now was stakeholder agreement on:
What problems needed solutions.
What “solved” means in clear terms from the perspective of the stakeholder.
The priority sequence of work for each helping outside expert.
This meeting, by the way, wasn’t necessarily pretty. But they needed to work through the conflicts themselves. No outsider could do that except to impose something, which would reduce the ownership of the process.
All of this effort was to make sure we were focused on workflow, not simply software features. All solutions had to be in the form of what someone had to do in order to advance the work.
Daily Management
We used sticky dots to indicate the status of each card. The colors were based on nothing more than the box of stickers I could find at the local wally-world.
When the outside expert began work on a particular problem, they would put a pink dot on the card. This signaled to everyone that this problem was “in work.”
If they encountered any issues or delays, they would put a post-it on the card saying what question needed to be answered, or what was needed to resume work. This indicated “Stuck” status and what must be done to get it “Unstuck.”
They typically worked with the individual Team Members who had to use the system to do their work. Sometimes, though, they had to get answers from outside, or even facilitate modifications to the system.
When the outside expert believed the solution was Ready to demonstrate to the Stakeholder for buy-off, they put an orange dot on the card.
They also moved the card to another column on the wall under the stakeholder’s name. This established the work queue for the stakeholders. It was now their responsibility to initiate the next action. It was clear who was waiting for who.
Once the stakeholder was satisfied with the solution, they (and only they) applied a green “Verified / Complete” dot, and the card was moved to the “Completed Items” section of the wall. That showed we were making progress.
Process Guidelines
We also established agreement around workflow guidelines, a set of loose standards to strive for in a solution.
Staying Aligned
We established a daily standup every morning at 10:00.
The purpose was to align on status. It was NOT to solve problems. The meeting took 10 minutes or less, each person speaking for less than 60 seconds. This was the time to mention if you were blocked on making progress, or if you needed help.
To facilitate the structure we used a “talking stick” – something that was passed from person to person indicating it was their turn to talk, and that everyone else’s task was simply to listen. Question, discussions, possible solutions, etc. were, “I can help with that, let’s meet after” and the meeting was typically followed by quick 2-3 person huddles.
Transparency = Progress
By having everyone working toward a shared Truth that was displayed for all to see, there was no opportunity for speculation, wondering who was working on what, why progress was stuck.
Possible solutions were investigated, and results reported at the daily standup, AND on sticky notes on the cards.
Everyone know if the next step was their responsibility (because the card was on the wall under their name).
There were no action item reviews, no “I’ll have that done next week.” Every task was on a timeline of Today and Tomorrow.
At the same time, this process was a shock to the organizational culture which was pretty much the opposite of everything I just said.
Many years ago I worked with a senior manager. He was very savvy about continuous improvement and TPS – he had been engaging in the space for many years before the word “lean” entered the lexicon. He understood it at a deep systems level, saw how all of the pieces interacted into a coherent whole, and was incisive in his observations (in spite of his disarming demeanor that led one to (wrongly) conclude he only saw superficial things.)
Like many of us, though, he was searching for a concise way explain how it all works to others. I think his underlying assumption was something like, “If they could just understand the system, then they would adopt the principles.” That, then, translated to, “If I could just explain it well enough, they would understand it.”
What I saw was that he was continually trying to create the ideal model, diagram, that he could use to create this enlightenment.
It seems so simple. The foundational principles are simple. It is putting everything into consistent practice that is daunting. The organization, as a whole, has to learn to think differently.
I used to do the same thing – maybe because he was a bit of a mentor to me, and I was often a sounding board for his latest models. Those were incredibly [some superlative word here] conversations because I, like he, really enjoyed having my systems thinking pushed by someone willing to challenge it (and vice-versa).
In the end, though, I think this is a futile exercise. He and I could have that conversation because we both deeply understood what we were attempting to explain. But our understanding was gained through years of trying it and learning from whatever results we observed.
What I know today is the nature of the questions to ask, with the intent of provoking thought, but I am carrying the belief that my role is to help shape their journey through their own discovery of how it all works.
What has been your experience with the perfect model?
Continuing on the theme of value stream mapping (and process mapping in general) – in the last post, Where is your value stream map? I outlined the typical scenario – the map is built by the Continuous Improvement Team, and they are the ones primarily engaged in the conversations about how to close the gap between the current state and the future state.
The challenge here is that ultimately it is the line leadership, not the Continuous Improvement Team, that drives whether or not this effort is long-term successful.
Getting a continuous improvement culture into place means changing the day-to-day patterns of interaction between people and groups of people. We can put in all of the lean tools we want, but if those conversations don’t follow, the system quickly reverts to the previous baseline.
What is interesting (to me, but I admit I’m a geek about this stuff) is that this is a meta level thing. While we are working on improving the performance of the value stream, we really have to be working on the performance of the process of leadership in the organization.
The value stream map can help with this, but we have to be deliberate about it, and realize that it will be an incremental and iterative process, just as we find in trying to improve how any process functions.
Start With Where You Want To Go
For line leadership, before we even start drawing process boxes, the first step is deciding why you are even doing this. What problem are you trying to solve? What aspect of your current performance needs to change… dramatically?
Is your system unresponsive to customers? Do customers expect deliveries inside your nominal lead times? Does that disrupt your system? What lead time capability would let you routinely handle these issues so they weren’t even issues anymore, just normal operations? That objective is going to bias your current state VSM toward understanding what is driving your lead times, where, when, and for how long, work is idle vs. actually being processed, etc.
Or maybe you need to increase your capacity while holding your costs (vs. just duplicating the existing processes). Now you are going to be focusing on the things that constrain your throughput, activities that consume time within cycles of output and the like.
Establishing that focus is a leadership / management task. It doesn’t work to just say “We need to improve” or even worse “We need to get lean.”
Sometimes these things are obvious frustrations to management, but often they are overwhelmed with general performance issues, or trying to define problems in terms of financials. That is an opportunity to focus back on the kind of performance that would address the financials.
The cool thing here is that you really can’t get this wrong. If you set a goal of radically improving your performance on any single aspect of your operation, you will end up improving pretty much everything in the process of reaching that goal. But it is critically important to have a goal to strive for, otherwise people are just trying to “improve” without any objective.
Then map your current state. The challenge gives you context. The current state map gives you a picture of how and why the system performs as it does.
Just so we don’t get sucked down the whirlpool of focusing too much on the business process in this discussion, the reason why you are getting this clarity is to get (and keep) the leaders engaged. If the objective is something abstract like “get lean” it is easy for them to think they can just get updates while they deal with the “real issues.” We want to attach this to a real issue that they are already working on.
Thus there is no “lean plan.” So many companies make “lean” somehow separate from other business objectives. I never could understand that. Maybe they are trying to separate “gains” that are a result of the “lean program” from those created by other initiatives. It doesn’t work that way. There is only one operating system in play, and that is what drives your day-to-day performance. If you don’t like the performance, you have to change the operating system. That is a management function, and it can’t be delegated.
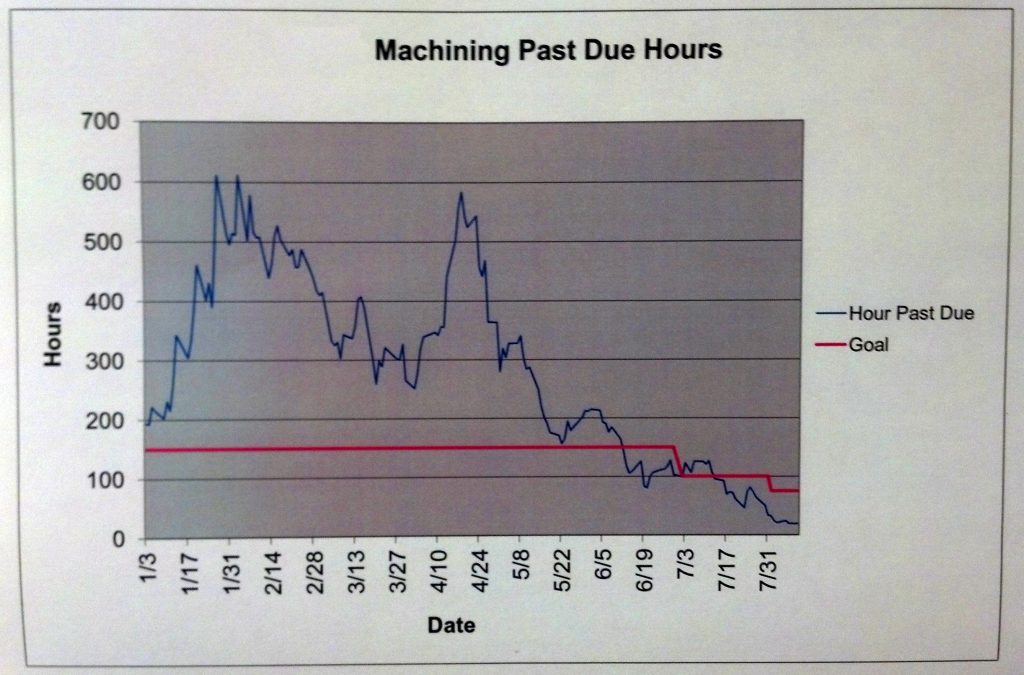
The photo above is a current state map from a process that took several weeks to ship a part that the customer had ordered. Since it was a make-to-order shop, this was, shall we say, challenging for the customer relationship people.
As the team built the map it began to sink in that the time actually making the part was less than 30 minutes, and the value add was about six of those minutes. Their performance metric was “Past Due Hours” which was an abstraction of the programmed jobs that were behind the promised ship date.
Because the customers were always asking the business team members, “Where’s my stuff?” those customer reps were, in turn, always on the shop floor trying to get their orders expedited. They were competing with one another for a place in the production queue.
There is an icon in the middle of the map. Here is a close up:
This is Jim. He was an hourly associate whose nominal job was to pull the paperwork, match it up with raw material, and stage the work package into the production queue.
But this role made him the gatekeeper. So the customer service people (you can see their names in the lower left corner) would be pressuring Jim to jump their hot orders (and they were all hot by the time it got to the point where there was paperwork release – another story) into the queue so they could tell their customers that their orders were “in production.”
This put Jim in the position of having to make the priority decisions that the leadership wouldn’t make. Ultimately it was Jim who decided which customers would be disappointed that day. That made his day way more stressful than his pay grade. Respect for people? Hardly.
It also resulted in a staged order queue (materials and paperwork on carts) that snaked through the shop until it finally (days later) got to the actual production cell which, once they started, could actually knock things out pretty fast.
None of this addressed the past due issue. In fact, this made it worse.*
The key question for this team was “Who needs to have what conversation about work priorities so it isn’t all on an hourly associate to decide which of our customers will be disappointed?”
Who Needs To Fix This?
We want to solve problems at the lowest possible level, but no lower. In this working example, asking the shop floor workforce to fix this problem would be futile. Yes, they can propose a different structure, but they do not control how orders are released, they do not control how capacity is managed, they do not control the account managers who are fighting for a spot in the queue. They had been complaining about this bind for a long time. It wasn’t until the people running the business saw how the overall system worked that they understood that this is a systemic issue, and “the system” belongs to line management.
The facilitation question that got their attention was “Do you want Jim to be the one who decides who gets production priority?” Of course the answer was “No.” And that wasn’t about Jim, rather it was the realization that this WAS the existing process, and that wasn’t how they wanted things to operate. As my friend Brian says, “You may not like your normal, but you have to deal with it.”
That is generally the case at the value stream level. Value stream problems are usually at the interfaces between processes. The shop floor can’t, for example, transition from a push scheduling system to pull on their own. If they try, they create conflicts with the existing scheduling system and this usually tanks their metrics – even if performance is actually getting better.
These are all management discussions.
Key Point: The value stream level is a systems view. While you absolutely want input from the people who are engaged in the work every day, working on the system itself is not something that can be delegated by line leadership. They are the ones who are responsible for the overall system, and they are the ones who need to be responsible for changing it.
The Future State Map is a Hypothesis
Once you understand the current condition, the next step is to answer the question, “How does the process need to operate in order to meet our goal?”
The purpose of mapping a future state is to design process flow that you believe will meet your challenge if you can get the system to work that way.
It isn’t about seeing what you could do by removing waste. It isn’t “what could we improve,” it is “what must we change to reach our objective?” Again, this is a management function. It’s called “leadership.”
Which brings me to the title of this post.
Who Is Talking About This Stuff?
If the Continuous Improvement Team simply facilitated the process for line leadership (the actual stakeholders) to grasp the current condition and establish a target (future state) condition, what is crucial is who takes ownership of closing the gap. If the C.I. team are the ones discussing the problems they are often in a position of having to sell and justify every step of the effort to get to the future state.
Likewise, I have seen a lot of cases where the people primarily participating in building the value stream map were working level team members. Yes, it is absolutely necessary to have their insights into how things really are for people trying to get stuff done. Yes, it is critically helpful for them to understand the bigger picture context of what they do. However, all too often, I see senior leaders disengaged under the umbrella that they are “empowering” their workers.
Just to be clear: We absolutely want to create conversations about improvement at the level of the organization where value and the customer’s experience is actually created. The point here is that those conversations cannot be the exclusive domain of the working levels. It is critical for line leadership to be, well, leading. They can’t just delegate this to the continuous improvement specialists. Nor can they simply leave it to the working levels to sort it out – not if they expect it to work for any length of time.
Who reports on progress?
When an executive wants to know the progress toward an improvement goal, who do they call? Do they call the continuous improvement team to report? Or do they call the actual stakeholder who is responsible?
This is an easy trap to fall into. The C.I. Manager wants to show they are making a difference. The senior manager knows the C.I. Manager probably has better information. But that isn’t the conversation we want to create. The conversation needs to be between the line leaders. Yes, the C.I. team can (and probably should) help structure that conversation, but if they inject themselves into the middle (or allow senior management to put them there) the vital vertical connections are weakened – if they ever existed.
Thus, it is critical for the Continuous Improvement team to have a crystal clear picture of who should be having these conversations, and be actively working to nudge things in that direction. This is the process the C.I. team should actually be working to improve.
What should people talk about?
Ah, here’s the rub. For some reason managers today have a reluctance (or even disdain) to talk about operations, preferring to keep conversations in financial terms of cost, earned hours, yield and the like. These are all outcomes, but they are outcomes of process, and it is only by changing the process that those outcomes can sustainably change.
That conversation about progress I talked about above? That can’t be solely about the performance. It has to be about what is changing in the way the work is being done, and more importantly, what is being learned.
What the future state value stream map does (or should be used to do) is translate those business objectives into operational requirements for the process.
What Is Your Target Condition?
How we start to see the organic intersection between Toyota Kata and the value stream map.
The future state map defines a management goal. It also highlights the problems that must be solved to get there. (Those are the “kaizen bursts” that Learning to See has you put on the future state map.)
Those problems, or obstacles in Toyota Kata terms, at the value stream level become challenges (again in Toyota Kata terms) for the respective process owners.
Now the conversations move to the right level. Rather than asking for the status of action items for the “lead time reduction initiative,” the line leaders are discussing progress toward getting the changeover in stamping down to 17 minutes, and the cycle times in the weld cell under the takt time.
In my working example above, the first target condition was to have Jim simply pull the next order from a FIFO queue in a series of slots on the wall. The customer service reps had to meet every morning and could reshuffle the orders in those slots all they wanted, but Jim’s job was just to take the next one. That pushed the initial conversation to the one they had been avoiding: The customer service team talking among themselves, rather than making Jim the arbitrator.
There was a lot of other work as well. They established a rigid FIFO with a fixed WIP level of staged orders. Instead of pushing days of work into that queue, there was a buffer of about an hour (to absorb variation in processing times between various jobs).
At the same time, the team running machines now understood the rate of processing that was required to keep up with the volume of work. That had been totally hidden by the queues before. All they knew is that they were behind. Now the conversation shifted to “Are we going fast enough?” It shifted from discussions about backlog (which really are not productive) to discussions about rate of processing which is the only thing that affects the backlog.
Getting all of this dialed in and stable took a few weeks of daily conversations between the Operations Director and the various managers and supervisors whose work impacted the flow. It involved walking the floor, putting in visual indicators that clearly defined what should be happening – the target condition – and they discussed reasons things looked different: The actual condition now, and what obstacles were being surfaced as they worked to reduce the WIP buffers.
The net result?
Learning is Critical
The current performance is an outcome of the current system. People do their best within the system they have to work within, and we have to assume the system reflects management’s understanding of how things should operate to get the best results.
Even if someone knows a better way, that knowledge is wasted unless it is applied to the overall system of operating – the way we do things.
Epilog
You would never say “The freezer is cold enough, we can unplug it now.” You have to keep putting energy into the system just to keep the temperature where it is. Tightly performing production systems are no different. Over the course of the next year or so past due hours slowly crept back up for unknown reasons. Why? Because they didn’t talk about it every day.
*When a shop is behind, the management reflexes are (1) increasing batch sizes and (2) expediting. There really aren’t any better ways to make the throughout and response times worse.
Lately the term “socio-technical system has been starting to show up more and I thought this would be an opportunity to weigh in on what I think it means.
Though the concept has been around since at least 1951 (see below), I think I have tended to “bleep over” the term as jargon without giving it a lot of thought. I don’t think I am alone in that.
People who try to describe the meaning tend to describe a system “that integrates the social and technical aspects” or words like that.
I would posit that it goes much deeper, and we “bleep over” the concept at our peril if we want our organizations to function well.
The Origin of Social-Technical Theory
*Up through the 1940s, coal mining in the UK was largely pick and shovel work aided by drills and, sometimes, explosives. A work crew typically consisted of three to half a dozen men (and they were all men) who were task organized to strip the coal off the seam face, shovel it into mining carts, and move those carts to the transport system.
These teams were distributed through the mine, and because the distance and working conditions really precluded a lot of supervision, the teams largely oversaw their own work.
Since each team worked independently, the system as a whole could easily accommodate the simple fact that in some spots the coal is harder to dig out than in others.
The work also met every definition of “difficult, dirty and dangerous.” That work environment, though, created a social bond among the team members as they worked together to accomplish the task of “mining coal.”
The system was not without its problems, however. The social structure was built around loyalty to the small work team. When “trams” (coal carts) were in short supply, for example, the “trammers” would horde carts to optimize their team’s performance at the expense of other teams being limited by the number of carts available.
This all changed shortly after WWII.
The Long Wall Method
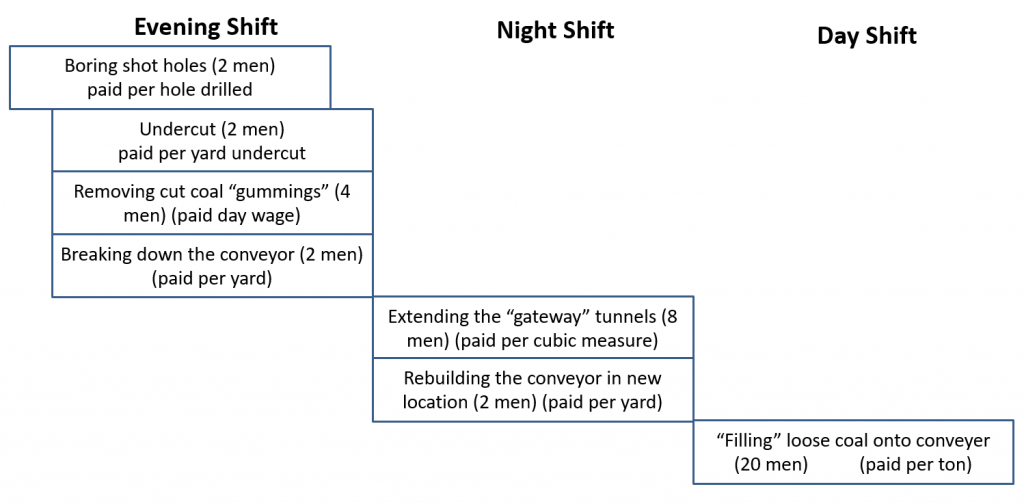
In the late 1940s the industrial engineers turned this craft production system into a factory system with the tasks divided between three shifts.
Long Wall Mining Shift Schedule
The process would begin on the evening shift. They would drill blast holes along the top of the coal seam, then dig an undercut about six inches high at the base to allow the blast to drop the coal. This would be done along a long (up to a couple of hundred meters) face of the coal seam. (Hence the name “long wall mining.”)
Meanwhile another team would break down the conveyor system that ran parallel to the coal face in preparation for moving it forward to position it for removing the loose coal.
Then night shift had two teams. One would extend the “gateway tunnels” at either end of the coal face. This was a crew of 8 men. Simultaneously another team would rebuild the conveyer in the new position.
Once all of this work was done, the shots would be fired, dropping the coal into a pile along the coal seam face.
Day shift would take the loose coal and transfer it to the conveyor system to be taken out of the mine.
Yes, this is an oversimplification, but it suffices for this discussion.
On paper, this process was far more efficient.
In practice, though, things did not go smoothly.
“Isolated Dependence”
A “filler” loads loose coal onto the conveyor.
Looking at this work breakdown, the first two shifts are prep work. Only the day shift, the “fillers,” actually get the coal out of the mine. But their success was entirely dependent on how well the first two shifts did their jobs. If everything was not “by the book” then the fillers would be significantly hampered. Since they were paid by the ton of coal extracted, there was more at stake than just a sense of accomplishment.
If the previous shifts ran into problems – such as a “shot” that failed to separate all of the coal from the roof of the seam, or harder material, etc. these inconsistencies slowed down the “fillers” and made them less successful. If the conveyor was not completely or correctly assembled, they could not begin work until this was corrected.
Because management pressure was on the key performance indicator – the rate of coal extraction, and because the “fillers” were paid by the ton of coal extracted, this created resentment between the “fillers” and crews on the other two shifts, as well as conflicts with management which the working crews began to regard (with ample evidence) as disconnected from the realities of their work.
Then, if the “fillers” were too far behind at the end of their shift, that would delay the start of the next cycle and things spiraled downward from there.
Productivity plummeted. The study I am citing here was commissioned to determine why. Their conclusion, in short, was that the new work organization was built around the paradigm of a factory assembly line without regard for the variation of geology. Success of the three shift cycle depended on each shift meeting a rigid schedule, but that schedule did not account for the simple fact that coal seams are not uniform.
In addition, the work organization destroyed the social structure of the mining crews. Their success was dependent on people they no longer saw or interacted with. The oncoming filler shift, in particular, would be confronted with all of the obstacles left by the previous two shifts. As their resentment for being unsupported built, their willingness to put in any extra effort dropped to zero.
Again – this is an oversimplification. If you want to read the full paper there is a link at the end of this post.
Oversimplification or not, however, the effect was stark. The social structure of the organization was driven to fundamentally change by alternations in the technical structure of the work. Quoting from my source material* :
The effect of the introduction of mechanized methods of face preparation and conveying, along with the retention of manual filling, has been not only to isolate the filler from those with whom he formerly shared the coal-getting task as a whole, but to make him one of a large aggregate serviced by the same small group of preparation workers.
The work design was based on a mechanistic view that ignored the how the social structure impacted the performance of the team.
By the turn of the last century we thought we had the ways of the universe pretty well understood. Hundreds of years (thousands of years in some early societies) earlier we had the ability to predict the motion of the stars and planets – to the point that we could build machines that were analogues of their movements.
The prevailing model in psychology was classical conditioning which, in essence, said that behavior is an almost algorithmic learned response based on previous positive and negative reinforcements.
This mechanistic model leads to a belief that we can carefully design the machine and people’s work within the machine can be carefully designed and shaped through rewards and consequences.
And as long as everything, and every one, works as they are supposed to, it’s all good. If a machine malfunctions, we fix it. If people don’t follow procedures, we “motivate them” with incentives.
This model prevails even today and even colors our teaching of continuous improvement. One of the places we need tend to inherently adopt a mechanistic view is when we use the word “system.”
The Mechanistic View of “System”
In today’s world, when people talk about “the system” they are often referring to an information system of some type. Common examples are an Enterprise Resource Planning (ERP) system, or an Electronic Health Records (EHR) system. And these information processing systems do tend to shape how the organization functions, for better or for worse.
So when people talk about a “system” I think the reflex is to think of the system as a machine that is carefully designed, built, and tuned to perform a particular function or behave in a particular way.
And people tend to assume that once it is working, it will continue to work so long as it is maintained to be kept in the same condition.
This thinking often extends to the people as well. They are often viewed as servicing “the system” – providing it with information, and following the instructions it gives. (this is particularly true in ERP / MRP environments.) Everything is part of a machine, and as long as everyone does their jobs, and the equipment functions as intended, then it all works.
In practice, though, these systems tend to isolate people from one another, or into small single task groups in much the same way as happened in the coal mine.
The Mechanistic Paradigm at Work
The reason I explained all of this is so we can look at our own workplaces through this lens. The crucial question is: Do the work structures and systems support or hamper the social structure of effective teamwork?
Let’s take another look at those ERP or EHR systems. Without the interaction with and the interaction between the people who use them, those “systems” are inert. They do nothing. The mechanistic paradigm, though, tends to look at people as performing a task to serve or enable the system. Instead, we should look at the information system as a tool that should enable people do to a job they otherwise could not.
On the Shop Floor
The sign says “Hearing Protection Required.” The reality is that it is impossible for more than 3 or 4 people to have a conversation on the shop floor, as they are shouting to be heard. The final operation is highly automated, each machine has two people working in isolation, even from one another for the most part. In addition, the machine crews are isolated from one another, both by distance and by the noise level.
The machine operator is measured on his hourly rate of production vs. a standard expectation.
Meanwhile at the opposite end of the building, the production scheduling team works to carefully orchestrate the availability of packaging materials, purchased components, as well as scheduling each phase of production so work is available for the next step.
They do all of this with their ERP system and every day they create orders to issue components, production orders to the various areas in the shop, and purchase orders to their suppliers. They adjust priorities at least daily, based not only on lead times and changing customer requirements, but also on the reality of what has actually been produced, or not, up to this point. Items are early, they are late, production runs ahead, though mostly behind, the scheduled intent.
Everyone is frustrated. The planner / schedulers because production never seems to make what they planned. And production because scheduling never seems to schedule things that can be made with the available materials, etc. Shortages are discovered, an ad-hoc plan is created to keep things moving – but that may well consume components that were earmarked for something later in the week, and the cycle continues.
To make things even more interesting, the planner / schedulers are using production capacity numbers that they know are higher than reality. They are under pressure to put in unrealistic numbers because the real numbers would make the site’s cost estimates too high and attract scrutiny from corporate.
This means “the system” produces schedules that cannot be met by actual production even if everything else works, which, in turn, means continuously over-promising, under-delivering, and adjusting priorities.
Though the work is very different, we have a social structure not unlike the British coal mine.
This is what “isolated dependence” looks like in today’s work environments. If you are seeing blame casting and conflict between groups who are dependent on one another you likely have a similar situation in your organization.
Counter-Productive Response
Unfortunately the typical management response is to increase monitoring, control, incentives, “accountability” on individual parts of the process rather than looking at the entire system.
These things tend to increase the sense of isolation and frustration as they can create a sense of victimhood between the separate groups. For example, in the above situation everyone there told me that they used to have pull system on the factory floor, and it had worked really well, operated predictably, and gave them a lot more insight into what was actually happening. But some time ago a new management team wanted to track everything in the computer “for control” so the current system was installed.
Ironically, that management team had turned over, but for whatever reason people were very reluctant to return to what they knew had worked in the past. But I digress.
The Implications
Human beings are innately social. In any organization, or casual group trying to get something done, people develop webs of social networks. The more they can interact, the more everyone stays on the same page.
There are a few things we can do to reinforce this.
Bring People Together
And I mean bring them together literally, physically. Rather than just confronting one another in the morning meeting, have them literally work side-by-side with the common goal of a smooth process.
Have a Shared, Objective, Truth
Eliminate the need to ask or query “status.” Eliminate the one person who knows the big picture. Get the truth out there in the open– literally, physically. (See a trend here?)
In a well managed operation I nearly always find rich “information radiators” that are an inherent part of the process itself (rather than being a display of information that was input just so it can be displayed). This information is not simply a passive display. It is actively used by the people doing the work to they know where they stand, what comes next, and when they need to raise a concern.
A classic example of this is a heijunka or load-leveling box. The cards, or work orders, or pick tickets, are placed in slots that are based on the time that work is expected to start if everything is working normally. Thus it is insanely easy to spot if something is getting behind, long before it would show up in the daily production report. Menlo Innovations’ Work Authorization Board does the same thing.
The goal is for conversations to be about “How to respond” rather than discussions about “what is happening.”
This is really the purpose of nearly every “lean tool” — to ask, and answer, two key questions:
What should be happening?
What is actually happening?
and then invite a conversation about any difference between the two.
The fact that “we have made 234 widgets” is meaningless without a point of comparison of “how many widgets should we have made up to this point?” The goal is to invite curiosity and foster actual conversations, and eliminate debates about what should be and what actually is.
But more often, this is what I most find lacking. People well tell me they can easily query status, look up individual orders, but even then there is rarely a timely comparison between “nominal” and “actual” in that information. Even if status can be queried, there is often a lack a “compared to what?” Or worse, the status is abstracted from reality, for example, measured in “earned hours” or some other financial metric. Often “ahead or behind” is not known until the end of the day… or the week, or sometimes even the month. The greater the lag, the bigger is the scramble to make up production with overtime.
So here is question #1 for you: If I were to ask you, right now, “Is this operation ahead or behind?” could you tell me? Can the people who are actually doing the work tell me? And by “tell me” I mean immediately, without having to go research or launch some kind of query.
Another version of this question is, “How far behind do you allow yourself to get before you actually know there is a problem?”
Social-Technical
So what we have is a technical aspect of a process that is deliberately designed to support meaningful social interactions between the people responsible for carrying out the work and accomplishing the overall task… as a team. We bring people together rather than isolating them from one another.
This is hard – Yup.
And these principles run against management “best practices” that have been taught since the 1920s.
Where to start? If any of this seems impossible, work on trust. Think about this – Why would people be reluctant to display an objective truth without the ability to first qualify it?
Why would people be reluctant to create a true dependent relationship with another department?
All of these things come down to a culture of self-defense because people feel a need to protect themselves from something or someone. Even if that force is long gone, the effects of leadership-by-fear linger, sometimes for many years, unless you take proactive and direct steps to eliminate that fear.
Once again I am going through old files. These are some notes I wrote back in 2005 that I thought might be interesting here. Looking back at what I was writing at the time, I think I was thinking about nailing these points to a church door somewhere in the company. That actually isn’t a bad analogy as I was advocating a pretty dramatic shift in the role of the kaizen workshop leaders.
All Saint’s Church – Wittenberg, Germany
This was written four years before I first encountered Toyota Kata, and reflected my experience as a lean director operating within a $2billion slice of a global manufacturing company. What reading Toyota Kata did for me was (1) solidify what I wrote below, and (2) provided a structure for actually doing it.
Perhaps this will create some discussion. If you are interested in getting a Zoom session together around it, feel free to hit the Contact Mark in the right sidebar (or just click it here) and drop me a note. If there is interest, I’ll put something together.
Kaizen Events
Kaizen events (or whatever we want to call the traditional week-long activity):
Can be a useful tool when used in the context of an overall plan.
Are neither necessary nor sufficient to implement [our operating system].1
There are times when any specific tool is appropriate, and there are no universal tools. Kaizen tools included.
(Our operating system) is, by our own model, the “Operational Excellence” pillar of (our business system). This is keyed in leadership behavior, not implementation of tools. The tools serve only to provide context for leaders to rapidly see what is happening and the means to immediately respond to problems.
Thus, focusing on implementing the tools of TPS (takt time, flow, pull, etc) outside of the immediate response and problem solving context is an exercise which expends energy and gains very little sustainable change. This is independent of whether it is done in a week-long intense event or not.
However, in my experience, organizations which take a deliberate and steady approach implementing have had more success putting the sustaining mechanisms into place. While it is sometimes necessary to bring teams together for a few days at times to solve a specific problem, or to develop a radically different approach, these efforts tend to be more focused than a typical kaizen week I see.
When the kaizen week is scheduled first, and then the organization looks for what needs improving, this is a symptom of ineffective use of the tool.
In general, a kaizen, whether it is a week, a month, or even just a few minutes, must be focused on solving specific problems which are impeding flow or are barriers2 to the next level of performance. Without this focus, there is no association with the necessities of the business, and no context for the gains.
There are a few simple countermeasures which can be applied to a kaizen week activity that focus the participants much more tightly on learning the critical thinking.
Improvement can, and must, take many forms. A week-long kaizen activity is but one. It is expensive, time consuming, disruptive, and should be used deliberately only when simpler approaches have failed to solve the problem.
Classes and Courses ≠ Teaching and Learning
Bluntly, even though we preach PDCA and say we understand it, we are not applying PDCA in our education approach.
Some fundamental tenets:
All of our teaching should be contextual and focused on what skill or knowledge is required to clear the next barrier to flow or performance.
The above does not rule out teaching fundamental theory, but fundamental theory must be immediately translated into actions and put into practice or it will never be more than a nice discussion.
The vast majority of our teaching should be experiential, and based in real-world situations, solving actual problems vs. examples and contrived exercises.
We want to move our teaching toward an ideal state (a True North in our approach) where it is:
Socratic – focusing people on the key questions.
Experiential – learn by application to solve real problems and thus gain experience and confidence that the concepts translate to the real world.
Thus, education and training is but one tool used by leadership to help people clear the barriers and problems that block progress toward higher levels of performance.
As far as I can determine, the “Toyota Way” of teaching is similar to this model.
Content
The content of training is as critical as the way it is delivered.
Our objective is to shift people’s thinking, and in doing so, shift their day-to-day behavior as they make operational decisions. The target audience for all of our efforts are the people who make decisions which impact our direction and performance. This is anyone in any position of leadership, at any level of the company – from a Team Leader on the shop floor to the CEO.
The key is to embed the structure of applying PDCA into all of our content. For example:
Every tool, technique, etc. we teach, or should teach, is some application of the above. (The rules-in-use include problem detection, response, and problem solving.) I have yet to encounter an improvement tool or technique that does not fit this model.
This approach fundamentally re-frames the concept of “problem” and what should be done about it.
The Toyota Production System (in its pure state) is a process which delivers a continuous stream of problems to be solved to the only component of the system that can think – the people. This is how people are engaged, and this is what makes it a “people based system.” Leave this out, and “people based system” is just hollow words. Nearly every discussion talks about how important people are, but then dives right into technical topics without covering how people are actually engaged — outside the context of a week-long kaizen.
The Role of “Workshop Leaders” in the (Continuous Improvement Office)
No one has disputed the critical make-or-break role played by the line leadership, not only in implementation, but even more so in sustaining.
Workshop leaders are generally taught to plan and lead workshops. The emphasis is on the week-long workshop logistics; on presenting modules in classroom instruction; and on the skills to facilitate a team through the process of making rather dramatic shop floor improvements.
In a typical (not saying it happens here) implementation scenario, it is the workshop leaders who go to the work area, do the observations (usually without a lot of skilled mentoring, and usually just to collect cycle times); build the balance charts and combination sheets; plan what will be changed; how it will be changed, set objectives, targets and boundaries.
They are the most visible leadership of the teams during the week, and they are the ones tracking and pushing follow-up and completion of open kaizen newspaper items.
The effect of this (which is fairly consistent across companies) is:
The standard work tools are something workshop leaders use during improvement events.
Cycle times, observations, and looking for improvement opportunities is something that is the domain of the workshop leaders.
Actually guiding the team members through the problem solving process is the job of the workshop leaders.
The supervisors and managers are there as team members, in order to learn by participation, from this outside expert.
The question is: Who is responsible to coach the line leaders through the process of handling the problems that the TPS is designed to surface in operation?
Once the basic flows are in place, there will be a stream of problems revealed. Those problems will either be seen or not seen. IF problems are seen, they will either be dealt with quickly, following good thinking, or they will be accommodated so they go back to being unseen. This is a critical crossroad for the organization…. and it is the behavior of the first and second line leaders, and the support they get from their leaders, that most influences whether the system backslides or continues to get better and better.
IF problems are seen, they will either be dealt with quickly, following good thinking, or they will be accommodated so they go back to being unseen.
Note: There is not middle ground. One-piece-flow really can’t sustain in a stable state. It is either improving or getting worse. It isn’t designed to stay still, and it won’t. Continuous intervention is required for stability, and that intervention is what improves it.
Who is teaching the leaders to do this?
Each leader must have a coach, by name, who can, and will, always challenge his thinking and his solutions to problems against a specific thinking structure.
My view is this is the primary role for the Kaizen Promotion Office.
The way to do this is through application of a few core skills, and skills can be taught.
We should:
Include this vital role into the expectations of a “workshop leader” – to take them closer to being “coordinators” in the Toyota factory start-up model.
Provide these “coordinators” with a specific support process so they know that they can quickly get assistance if they feel they are in over their heads.
The role of that assistance is not to step in and solve the problem. It is to take the opportunity to teach both the workshop leader and the area manager by guiding them through solving the problem.
My experience with this concept is that teaching these skills to someone is not as difficult as most people assume. The basics of observing and seeing flows can be taught over a few days to someone who is motivated to learn. The skill of teaching by asking questions can be accelerated from the “pure” method by telling them what is being done in why. “This isn’t about the answers, it is about learning the questions.”
Application and good teaching can easily be verified by checking the leader’s (the student’s) level of skill and behavior. (The senior teacher checks the teacher by checking the student… just as the area supervisor checks the Team Leader’s teaching by verifying the standard work on the shop floor.
None of this is an advanced topic. These are the basics. Once a good context is established in people’s minds, my experience suggests that the Toyota system is no longer counter-intuitive. The tools and techniques that, at first, seem alien now make sense.
——–
1 By this I meant to shift the operating culture to one that inherently supports continuous improvement.
2 In Toyota Kata language, we would say “obstacles.” I had used the term “barriers” up to that point.
A long, long time ago – in the days when computer programs were coded as holes in punch cards – I was in ROTC* in college. Twice a year we had a “PT” (Physical Training, I think) test that consisted of measured performance on five “events.” One of those events was a 2 mile run. To get a maximum score of 100 points, the participant had to complete the 2 mile run in 14 minutes and 9 seconds. Why? I have no idea. But that was the way it was.
Yes – this old school stopwatch reads exactly 42 seconds.
My buddy John and I enjoyed running, and would often work out together. Our school was in Potsdam, New York, a place known for rather brutal winters, so we ran on a 1/10 mile indoor track.
We practiced the PT test. John would track our total time for 2 miles (20 laps around the 1/10 mile track). I would measure lap times. Since 14 minutes is 840 seconds, we knew that if we could consistently make 42 second laps, we would complete two miles in 14 minutes, and get the maximum score with 9 seconds to spare.
The track had hash marks at each quarter point, so we knew we had to hit quarter 1 between 10 and 11 seconds, half way at 21, the 3/4 mark between 31 and 32, and the lap at 42. We would check and adjust our pace accordingly, striving to hit exact 42 second laps every time.
To be clear, we could hold that pace many times further than 2 miles. It wasn’t a matter of conditioning. We weren’t going all out. We were going fast enough. And that was the point.
When we took the test, other cadets were going all out, passing us, and turning in much faster times. Others would try to “pace themselves” and then sprint as fast as they could for that last lap. As a general rule, although the instructors were calling out elapsed times as people went by, these cadets weren’t all that aware of the speed they had to hold. They were just going as fast as they could.
Meanwhile, John and I, running together, and tracking our cycle times (lap times) vs the takt time (42 seconds / lap) would come in at pretty much exactly 14 minutes and get the same score as everyone who had finished ahead of us: 100 points.
After our timed run was done, we would keep running, offering encouragement and pacing for those cadets who were struggling a bit. Everyone finishes, nobody left behind.
A couple of the instructors were curious why we didn’t go for a faster time. And many times we did when we were just working out. We were capable of breaking 12 minutes – not competitive times in a track meet, but respectable. The simple fact was that going faster wasn’t necessary to accomplish the goal.
Takt Time and Cycle Time
This is the whole point of having a takt time. It answers the question, “How fast must we go?” It doesn’t answer “How fast can we go?” nor does it answer “How fast should we go?” I fact, John and I could have run those laps almost (but not quite) half a second slower than we did – which would have eaten into the 9 second buffer we established. Aside from making the math easier, that buffer also gave us a small margin for even something as bad as taking a stumble and standing back up. Also, of course, we could make up 5-10 seconds a lap if we really had to. But we never did. Time: 14:00. We were very consistent.
Rate vs. Output
I encounter a lot of production managers who are so conditioned to focus on the daily output that they don’t even think about the critical factor: How fast are you running vs. how fast do you need to run? In other words what is your rate of output vs. your takt time?
Instead they tend to, at best, count units of output without really paying attention to the time interval between one and the next. In the worst case many units are started at once, and people swarm from one operation to the next during the day – the equivalent of that mad sprint trying to make up as much time as possible. They don’t really know if they will succeed or not until the end of the day (or month!).
It Isn’t a Race
The “just” in “just-in-time” is “just enough resources” to “just make the output you need” in any given time interval. As the operation is streamlined, the same effort is able to accomplish more. Where to put that additional capacity (which costs nothing additional since it has been there all along) to create more value should be the challenge the organization is trying to meet.
My experience has been that managers and leaders often struggle to adopt this “rate” mindset and let go of chasing an inventory number. In the words of the late great philosopher Kenny Rogers – “There’ll be plenty of time for counting when the dealings done.”
*ROTC (Reserve Officers Training Corps) is a U.S. program where college students can earn a commission in the U.S. Armed Forces while earning their degree.
MONDAY: 2 PERS 1 MACHINE. TODAY: 1 PERSON 2 MACHINES
On a Thursday afternoon in the summer of 1997 I sent that pager message (remember pagers?) to Rick from the factory where I had spent a week working with Mr. Shimura of Shingijutsu and Reiko, his interpreter.
I knew that Rick would be wrapping up a class teaching the basics of kaizen events to a group of suppliers and if I were lucky, he would see the pager message and use it as a reinforcement to the participants. Rick and I usually alternated teaching that class, sometimes we taught it together. We were good work partners, finishing each others’ sentences and the mutual respect was very high.
I was on-site at another supplier. We were there to help them take some first steps toward “lean production.” Our goal, at least the idea, was that we would work through the process of making significant improvements with the thought that they would learn enough to try it themselves.
This was not my first visit – the episode with Mr. Iwata that I relate in my third post to this blog had happened there a couple of months earlier, and that visit had resulted in my company offering up Mr. Shimura’s time on our dime.
This may well have been “an offer they couldn’t refuse” and I’m not sure everyone there saw it as help. We were from their 800 pound gorilla customer, they had trouble making on-time deliveries, and sometimes that isn’t the kind of help that you want. From their perspective their biggest customer had people who knew their way around a factory spending days on their shop floor and, most certainly, ascertaining how much more productivity was possible if only, well, the buyers squeezed them hard enough. It didn’t really work that way, but it had worked that way in the past, so who could blame the suppliers for thinking this was a more sophisticated way to audit them?
Anyway, we had worked through the week to carefully look at the tasks involved to unload, load, and machine a single part on a large linear milling machine. Mr. Shimura was there asking questions, not so much from curiosity but to direct my eyes. I’m sure he already knew the answers. As we dug into the timing, it became clear that there was enough operator waiting time as the part was being milled that a single operator could, theoretically, unload and load an adjacent machine – operating two of them at once.
So we carefully worked out the chorography required to make it work, and on Thursday mid-day it all came together. The work was flowing, the parts were flowing. It was really a thing of beauty.
Friday morning we would report out the week to management, and Friday afternoon I would head to the airport to go home to Seattle.
But I had some worries as well. Although the company President, and the VP of Operations were supportive, their support was along the lines of welcoming everyone into the plant, making it clear they were happy to see us, attending the final report-out and endorsing our efforts.
I was still pretty knew at this. I was making the transition from teaching classes and running simulations to making real change in real factories (that weren’t mine!). I was really fortunate to have a lot of 1:1 time with Mr. Shimura and Reiko. I asked questions, he patiently taught me how to use the standard work combination sheet, and other nuances of kaizen and flow production. I got a lot more out of that week than the supplier did simply because I was there spending time with Mr. Shimura and taking advantage of every second I could. I had 1:1 time because none of the supplier’s managers were seeking him out to learn from his vast experience.
Some quotes I will never forget: “If I see something is hand written, then I know at least one person has read it.”
“If parts that are in tolerance don’t fit, it is a problem with the tolerances.”
(Walking through the shop) “Does this company lose a lot of money?” Reply: “No, they are very profitable.” “Then their prices are too high.”
In the end, though, I am equally certain that come Monday morning the work sequence we had so carefully worked out – at great expense to my company for my time, my travel, Mr. Shimura, his interpreter, and others – was never repeated again.
Why not?
Well, we can all blame “management commitment” because that is really easy to do. But I put equal weight on our paradigm of improvement at the time. The idea that, in 4 working days we could institute a change that flew straight against the operational and cultural norms of the company and expect it to last any longer than until we were out the door was, well, ludicrous.
Why should we expect anything different?
It is ludicrous in any company, whether this work is being brought in from outside or internally generated.
The people who have to manage the daily work, whether they were involved in this exercise or not, have no paradigm for dealing with the myriad of issues that are bound to be surfaced after we pulled all of the buffers out of the material and the time. Yes, it can work, IF we understand the conditions required for success, and IF we pick up right away when those conditions aren’t there and IF we respond to fix it very fast. Then, yes, it can work.
It will be more time and trouble than it was before, though, unless the next things are also done.
For at least some of those issues – maybe not all of them, but always working against a couple of them – seeking out why those issues happened and dealing with the causes.
Just to keep this tiny two-machine “work cell” operating in this large factory would have eventually engaged every support system they had.
That’s the whole point, actually, of a model line. It isn’t building the model line. It is what you have to fix in your systems to keep it going.
Many years later I spent a week on another company’s shop floor with their internal kaizen team and getting an andon / escalation process up and running was the only thing we were working on that week. That process is just as important, if not more, than the baseline work of flow. Because without it, your flow will fall apart.
This is the part of the process that engages people. Putting in the baseline process is the easy part. Fielding the problems that flow surfaces – that takes changing the day-to-day routine in the workplace, and is a lot harder. That is where the culture change comes into play. Actually it is more than engaging people. It engages specific people: This is the part that must engage the leaders. They must lead, guide and coach process of working through all of the issues so stability can be reestablished. Then challenge the team to get to the next level.
But all of that is what I know now. I had the knowledge back then, but not the deep understanding.
So – I am thankful for that week because my understanding of what I had been teaching for months easily doubled… twice in those few days.
I was back there a few more times, they even gave me a badge (which I still have somewhere) so I could let myself in. One time I spent two straight weeks there. They were good people.
But we were applying work to the technical systems, and never really dealing with their default responses to problems, their culture, the way they went managing their daily work.
I know so much more today it is actually humbling to write this. And I still have a lot to learn. We all do.
The company I was working in? They were sold, and sold again. I think they are still in business, but I wouldn’t know anyone there.
I was going through some old files and came across a pocket card we handed out back in 2003 or so. It was used in conjunction with our “how to walk the gemba” coaching sessions that we did with the lean staff, and then taught them to do with leaders.
A lot has happened, a lot has been learned since then. Toyota Kata has been published, and that alone has focused my technique considerably (to say the least).
Nevertheless, I think the elements on these little cards are valuable things to keep in mind.
With that being said, a caveat: Lists like this run the risk of becoming dogma. They aren’t. There are lots of lists like this out there, and the vast majority are very good. The key here is something that a leader or team member can refer to as a reminder that may bias a decision in the right direction. It is the direction that matters, not the reminders.
Fundamentals
The fundamentals are based on the “Rules-in-Use” from Decoding the DNA of the Toyota Production System, a landmark HBR article by Steve Spear and H. Kent Bowen. The article, in turn, summarizes (and slightly updates) Spear’s findings from his PhD work studying Toyota.
A. All work highly specified as to content, sequence, timing, and outcome.
B. Every customer-supplier connection is simple and direct.
C. The path for every product is simple and direct.
D. All improvements are made using PDCA process.
What we left off, though, is that in each of those rules there is a second one: That all of these systems are set up to be “self diagnostic” – meaning there are clear indications that immediately alert the front line people if:
The work deviates from what was specified.
The connection between a customer and supplying process is anything other than specified.
The path a product follows deviates from the route specified.
Improvements are made outside of a rigorous PDCA (experimental) process.
In other words, the purpose of the rules is to be able to see when we break them, or cannot follow them, so we trigger action.
To put this into Toyota Kata-speak – every process is set up as a target condition that is being run as an experiment – even the process of improvement itself!
Every time there is a disruption – something that keeps the process from running the way it is supposed to – we have discovered an obstacle. That obstacle must first be contained to protect the team members and community (safety) and to protect the customer (quality). Then goes into the obstacle parking lot, and addressed in turn.
If you think about it, the Improvement Kata simply gives us much more rigor to (D).
This ties to the next sections.
Key Leadership Behaviors
Note that this is behaviors. These are things we want leaders to actually strive to do themselves, not just “support.” It was the job of the continuous improvement people to nudge, coach, assist the leaders to move in these directions. It was our job to teach our continuous improvement people how to do that coaching and assisting – beyond just running kaizen events that implement tools.
A. PDCA Thinking
Today we would use Toyota Kata to teach this. But the same structure drove our questioning back then.
B. Four Rules:
1. Safety First
Even though this should be obvious, it is much more common that people are tacitly, or even directly, asked to overlook safety issues for the sake of production. I remember walking through a facility with a group of managers on the way to the area we were going to see. Paul stopped dead in his tracks in front of a puddle on the floor. He was demonstrating just how easy it was for the leadership to walk right past things that should be attended to. And in doing so, they were sending the message – loud and clear in their silence – that having a puddle on the floor was OK.
2. Make a Rule, Keep a Rule
This is a more general instance of Rule #1. But the it is more subtle than it may seem on the surface. Most people immediately interpret this as enforcing organizational discipline, but in reality it is about managerial discipline.
Nearly every organization has a gap between “the rules” and how things really are day-to-day. Sometimes that gap is small. Sometimes it is huge.
Often “rules” are enforced arbitrarily, such as only cases where a violation led to a bigger problem of some kind. Here’s an example: Say your plant has a set of rules about how fork trucks are to be operated – speed limits, staying out of marked pedestrian lanes, etc. But in general the operators hurry, cut a corner now and then. And these violations are typically overlooked… until there is some kind of incident. Then the operator gets written up for “breaking the rules” that everyone breaks every day – and management tacitly encourages people to break every day by focusing on results rather than process.
When we say “make a rule / keep a rule” what we mean is if you aren’t willing to insist on a rule being followed consistently, then take the rule off the books. And if you are uncomfortable taking the rule off the books, then your only option is to develop something that you can stand behind. It might be simple mistake proofing, like physical barriers between forklift aisles and pedestrian aisles. But if you are going to make the rule, then find a way to keep the rule.
Do you have “standard work” documents that are rarely followed? Stop pretending you have standards or rules about how the work is done. Throw them away if you aren’t willing to train to them, mistake proof to them and reinforce following them.
3. Simple is Best
Simply, bias heavily toward the simplest solution that works. The fewest, simplest procedures. The simplest process flow. Complexity hides problems. “Telling people” by the way, is usually less simple than a physical change to the work environment that guides behavior. See above.
4. Small Steps
Again, Toyota Kata’s teaching covers this pretty well today. The key is that by taking small steps, verifying that they work, and anchoring them into practice before taking the next ensures that each step we take has a stable foundation under it.
The alternative would be to make many changes at once in the name of going faster.
We emphasized here that “small steps” does not equal “slow steps.” It is possible to take small steps quickly, and we found that in general doing so was faster than making big leaps. Getting big changes dialed in often required backing out and implementing one thing at a time anyway – just to troubleshoot! See “Gall’s Law” which states:
A complex system that works is invariably found to have evolved from a simple system that worked. A complex system designed from scratch never works and cannot be made to work. You have to start over, beginning with a working simple system.
John Gall, author of Systematics
and sums this up nicely.
C. Ask “Why, what, where, when, who, and how” in that order.
Here we borrowed the sequence from TWI Job Methods. The first two questions challenge whether a process step is even necessary: Why is it necessary? What is its purpose? To paraphrase Elon Musk, the greatest waste of time is improving something that shouldn’t even exist.
Then: Where is the best place? and When is the best time? These questions might nudge thinking about combining steps and further simplifying the process.
And finally we can ask Who is the best person? and “How” is the best method? The key point here is until we have the minimum possible steps in the simplest possible sequence, and understand the cycle times, it doesn’t make sense balance the work cycle or work on improving things.
Come to think about it – perhaps we should ask “How?” before we ask “Who” since improving the method will change the cycle times and may well inform out decisions about the work balance. Hmmm… I’ll have to think about that. Any thoughts from the TWI gurus?
D. Ask Why 5 Times
Honestly, this was a legacy of the times. Unfortunately it suggests that you can arrive at a root cause simply by repeatedly asking “Why?” and writing down the excuses answers that are generated. In reality problem solving involves multiple possible causes at each level, and each must be investigated. I talked about this in a post way back in 2008: Not Just Asking Why – Five Investigations.
E. Go and see.
Go and see for yourself. Taking this into today’s practice, I think it is something that the Toyota Kata community might emphasize a little more. We tend to ask the question “When can we go and see what we have learned…?” but all too often the answer to “What have you learned?” is a discussion at the board rather than actually going and observing. Hopefully the board is close to where the improvement work is being done. Key point for coaches: If the learner can’t show you and explain until you understand, it is likely the learner’s understanding could be deeper.
As You Walk The Workplace:
Check:
perhaps we should have said “Ask…” rather than “Check” but asking and observing are ways to “check.” All of the below are things that the leader walking the workplace must verify by testing the knowledge of the people doing the work.
A. How should the work be done? Content, Sequence, Timing, Outcome
This is another nod to the research of Steven Spear. The key point here is that before you can ask any of the following questions, you have to have a crisp and precise of what “good” looks like. In this paradigm, all processes are target conditions. And as the work is being done, we are actively searching for obstacles so we can work to make the work smoother and more consistent.
In other words, “What should be happening?” and “How do you know?”
Do the people doing the work understand the standard process as it should be done?
A few months ago I went into some depth on this here: Troubleshooting by Defining Standards. That probably isn’t the best title in retrospect, but there are too many links out there that I don’t want to break by changing it.
B. How do you know it is being done correctly?
Today I ask this question differently. I ask some version of “What is actually happening?” followed by “How can you tell?” We want to know if the people doing the work have a way to compare what they are actually doing against the standard.
C. How do you know the outcome is free of defects?
So, question B asks about consistency of the process, and question C asks about the outcome. Does the team member have a way to positively verify that the outcome is defect-free?
D. What do you do if you have a problem?
Again, we are checking if there is a defined process for escalating a problem. And we define “problem” as any deviation from the standard, or any ambiguity in what should be (or is) happening. We want someone to know, and act, on this, and the only way that is going to happen is to escalate the problem.
We want this process to be as rigorous and structured as the value-adding work.
And we want as much care put into designing production process as was put into designing the product itself. All too often great care and a lot of engineering time goes into product design, and only a casual pass is made at designing and testing the process.
Even better if these are done simultaneously where one informs the other.
For Abnormal Conditions:
ACT:
These are actions that the leader must take if she finds something that isn’t “as it should be” in the course of the CHECK questions above. Key Point: These are leadership actions. That doesn’t mean that the leaders personally carry them out, but the leaders are personally responsible for ensuring that these things are done – and checking again.
That is the only way I know of to prevent the process from continuing to erode.
A. Immediately follow up to restore the standard.
If it isn’t possible to get the intended standard into back place, then get a temporary countermeasure into place that ensures safety and quality.
B. Determine the cause of erosion.
We are talking about process erosion here, with the assumption that something knocked the process off its designed standard. Some obstacle has been discovered, we have to better understand what it is – at least enough to get it documented.
C. Develop and apply countermeasure.
Here we may have to run experiments against this newly discovered obstacle and figure out how to make the process more robust.
That is the end of the little card. But I want to point out that we didn’t just hand these out. You got one of these cards after time paired with a coach on the shop floor practicing answering and asking these questions. Only after you demonstrated the skill did you get the card – just as a reminder, not as a detailed reference. This exercise was inspired by a few of us who had experiences “in the chalk circle” especially with Japanese senseis who had been direct reports to Taiichi Ohno.
We piloted and developed this process on a very patient and willing senior executive – but that is another story for another day. (Thank you once again, Charlie. I learned more from you than you will probably ever realize.)
“Are you ahead or behind?” seems an innocent enough question.
But when asked by a Toyota advisor, the simple process of becoming able to answer it launched Liz McCartney and Jack Rosenburg on a journey of finding consistency in things that were “never the same” and stability in things that “always changed.”
Getting Homeis, first and foremost, a story. And, with the “business novel” being an almost worn-out genre, seeing a non-fiction story was refreshing. So when Chet Marchwinski from the LEI offered a review copy to me, I accepted.
For the story background, I’ll leave it to you to read the blurb on Amazon.* Better yet – read the book – and it is worth reading. I’ll say that right up front.
Yet with stories like this it is all too easy to dismiss them because they have different circumstances from “my” specific case and say “Yeah, it worked there, but won’t work here.”
I would contend, however, that in this case “it worked” in situations that are far more difficult than anything we are likely to encounter in most organizations.
What I want to do here is help pull their specific achievements into more general application – what lessons are here that anyone can take away and apply directly.
What They Achieved
I can’t think of a lot (any?) business circumstances that would have more built-in variability and sources of chaos than the process of rebuilding communities after a disaster such as a hurricane or flood.
Every client has different circumstances. The make, mix and skill levels of the volunteer workforce changes continuously. Every community has different bureaucratic processes – not to mention the various U.S. government agencies which can be, well, unpredictable in how and when they respond.
Yet they have to mobilize quickly, and build houses. This means securing funding, getting permits, mobilizing unskilled and skilled labor, and orchestrating everything to meet the specific needs of specific clients on a massive scale… fast.
How They Achieved It
When they first connected with their Toyota advisor, the simple question, “Are you ahead or behind?” prompted the response that drives all improvement, all scientific advancement, all innovation:
“We don’t actually know.”
Actually they did, kind of, but it was in very general, high-level terms.
And that is what I encounter everywhere. People have a sense of ahead or behind (usually behind), but they don’t have a firm grasp on the cause and effect relationship – what specific event triggered the first delay?
This little book drives home the cascading effect of ever deepening understanding that emerges from that vital shift from accepting things as they are to a mindset of incessant curiosity.
Being able to answer “Are you ahead or behind?” means you have to have a point of reference – what is supposed to happen, in what order, with what timing, with what result. If you don’t know those things, you can only get a general sense of “on track” or not.
They had to develop standards for training – what to train, how to train – volunteers! – , which meant challenging assumptions about what could, and could not, be “standardized.” (A lot more than you think.)
A standard, in turn, provides a point of reference – are we following it, or are we being pushed off it. That point of reference comes back to being able to know “Are we ahead or behind?”
It Isn’t About the Specific Tools
Yet it is. While it isn’t that important about whether this-or-that specific tool or approach is put into place, it is critical to understand what the tools you use are there to achieve.
As you read the book, look for some common underlying themes:
Information as a Social Lever
The project started revolving around the ahead/behind board.
In the “lean” world, we talk about “visual controls” a lot, and are generally fans of status boards on the wall. We see the same thing in agile project management (when it is done well).
These information radiators work to create conversations between people. If they aren’t creating those conversations, then they aren’t working. In Getting Home it was those conversations that resulted in challenging their assumptions.
Beyond Rote Implementation
Each tool surfaced more detail, which in turn, challenged the next level. This goes far beyond a checklist of tools to implement. Each technical change you make – each tool you try to put into place – is going to surface something that invites you to be curious.
It is the “Huh… what is happening here?” – the curiosity response – that actually makes continuous improvement happen. It isn’t the tools, it is the process of responding to what they reveal that is important.
Summary
Like the tools it describes, Getting Home is an invitation, and that is all, to think a little deeper than the surface telling of the story.
My challenge to you: If you choose to read this book (and I hope you do), go deeper. Parse it. Ask “What did they learn?” ask “What did this tool or question reveal to them, about them?” And then ask “What signals did they see that am I missing in my own organization?”
———-
*This is an affiliate link that give me a very small kickback if you happen to purchase the book – no cost to you.