I live on an arterial street about half a mile (800 meters) from Everett Fire Department Station 5, so it isn’t unusual to hear emergency vehicles go by.

Last evening, though, we heard a LOT of them, coming from not just Station 5, but elsewhere. Time to turn on the scanner.
“Fire, Residential, Confirmed” about 1.5 miles (2.4km) southwest of us. Over the next 30 minutes we listened in as the firefighters dispatched from stations 1, 4, and 5 methodically and deliberately found the fire (in the basement), searched the house (nobody was inside), and put the fire out.
As things were winding down, the battalion captain on site called dispatch to send out the fire inspector. When he arrived, they turned “command” over to him, and began their process of recovery and returning to service.
The inspector’s first priority was to make sure the home got properly boarded up, coordinate with the homeowners (who had a really bad day, but nobody was hurt).
But it is what happens next that I want to talk about.
Actually, first let’s put the story up to this point in terms of a classic problem escalation response.
Sidebar: Many years ago (2002?) I wrote an article titled The Essence of Jidoka for the SME’s online newsletter. In the article, I outlined a four step process that we had developed at Genie. As a sidebar, that article apparently was very popular, and I see that four step process repeated all over by consultants, in training materials, even in the Wikipedia article on the topic. So… if this process seems familiar to you, I didn’t take it from elsewhere, I literally developed it when I worked in Genie’s C.I. office. 😉
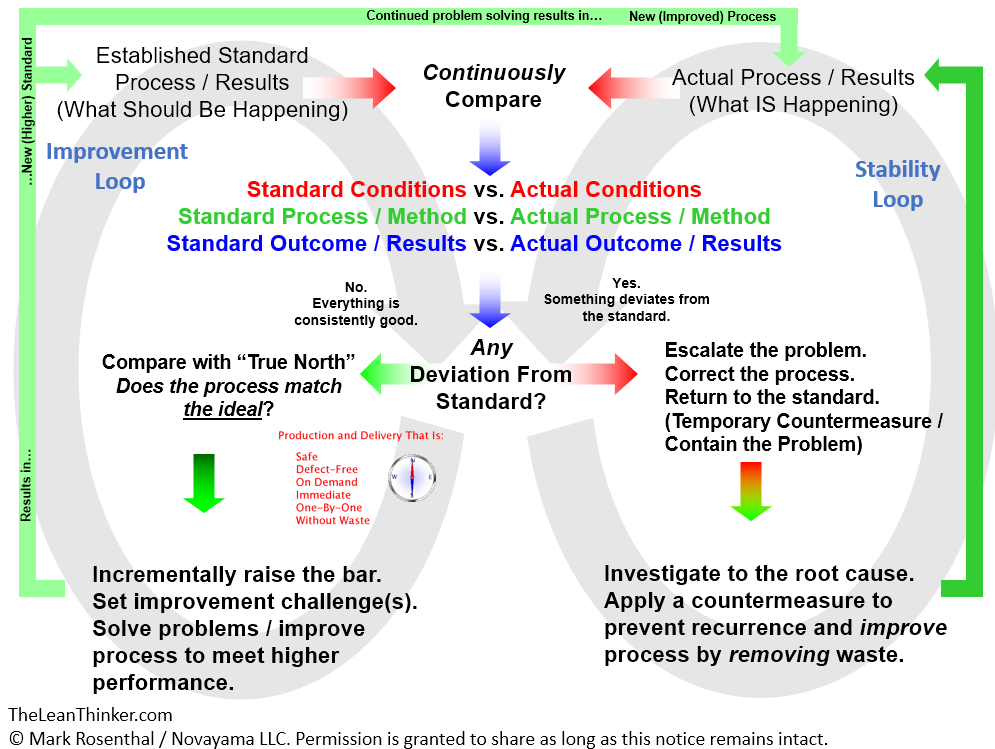
Step 1: Detect the problem.
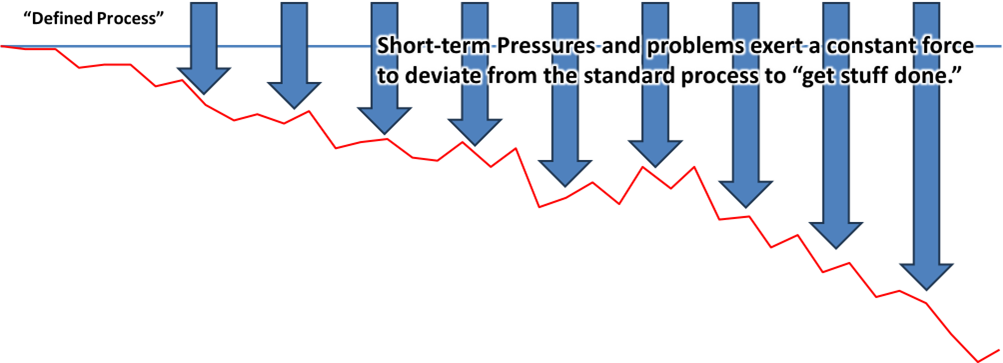
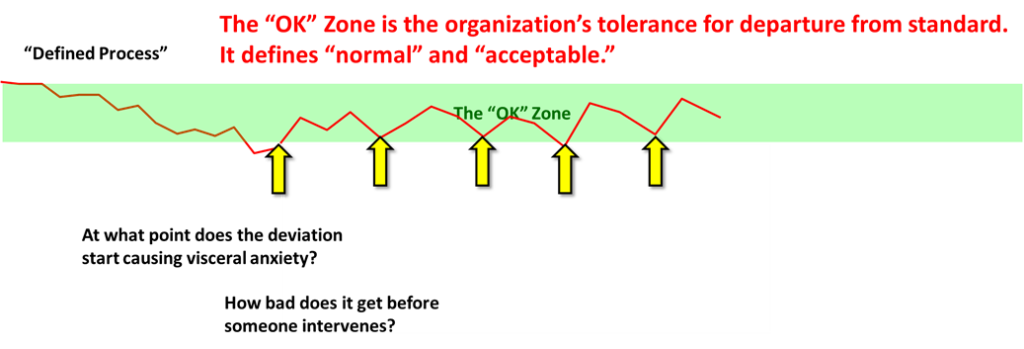
My Toyota friends were consistent in their definition of “problem” as “any deviation from the standard.” This will come back around, but in this case the first notice was likely a neighbor seeing smoke coming out of the house. Standard: There shouldn’t be smoke coming out of the house. Actual Condition: Smoke. Oh oh.
Step 2: STOP.
This means stop treating this condition as normal. It sometimes means bring everything to a halt. But it always means getting someone’s attention.
I set these out as two separate steps because people see anomalies all of the time and just continue, especially in situations where there is a lot of noise in the process. Circuit breakers trip, and someone just resets them. There is a funny sound or smell, but everything seems OK. None of these responses comes from a position of curious inquiry, which is what we need right now.
In this case, our hypothetical neighbor stopped whatever routine thing there were doing and called 911. (It may have been the homeowners, I don’t know. It was someone.)
Step 3: Fix or Correct the Immediate Condition.
The goals are to restore safety, and (in a production process) ensure that whatever is going to the customer conforms to specifications for quality.
In our example, the goals were get people out of harm’s way and put out the fire. The firefighters didn’t leave until that was done.
Now, there is a lot more do to here. The homeowners, their insurance company, and other stakeholders will be working together to restore things to something approximating the pre-fire condition. But all of this is still resetting to the original standard.
Step 4 is where the learning happens.
Step 4: Identify the Root Cause and apply a Countermeasure.
Some people may quibble with my term countermeasure here. Fine. Use whatever term you want that fits your jargon reference. In this case, I am talking about something that addresses why the fire started in the first place.
Remember that fire inspector? He is going to investigate, and there are, broadly, three possible outcomes for that investigation.
- A deliberate criminal act (arson). Not likely in this case, but they are going to rule that out first. Once they do, two broad possibilities remain:
- There was a condition that violated the fire code in some way. Going a bit beyond a literal application of the code, there were conditions which increase the risk of a fire starting. Somewhere, fuel, oxygen, and a source of ignition came together when and where they shouldn’t.
- OR, everything was compliant, but a fire started anyway.
I want to focus on #3 here.
London. September 2*, 1666.
Just as the day rolled to Sunday, a fire broke out in Thomas Farriner’s bakery along Pudding Lane.

There is controversy around the (in)decision to immediately stop the spread by demolishing neighboring buildings to establish a fire break – the prevailing firefighting practice in the days of dense buildings and unreliable firefighting infrastructure.
Regardless, by morning the fire had spread to 300 houses, and over the next four days it consumed 13,000 houses, 85 churches, and displaced about 15% of the city’s population.
What emerged: Standards.
I’m going to resist the temptation to detail how fire and building codes evolved over the following 350 years (you can thank me the next time you see me). During that time some lessons were learned again, and again, but there was steady improvement. Certainly by the mid-early 20th Century, we no longer had fires that devastated the entire core of modern cities.
Codes also evolved with technology. The introduction of electricity into buildings, for example, added a new wrinkle even as it slowly displaced many of the indoor open flames.
Those codes represent lessons. Each time there is a fire, the investigation revealed one of the three possible outcomes I outlined above. In the third case, the question to answer is, “What did we miss?” and “What have we learned?”
And to be clear, it wasn’t 100% the work of governments. Underwriters Limited, for example, was originally founded representing the interests of the insurance companies who want to minimize their payouts for claims.
All of this is greatly over-simplified, of course. The key point I am trying to make is this:
Standards Represent Accumulated Knowledge
In the past I’ve said many times that the purpose of a standard is to provide a point of comparison between what should be (the standard) and what actually is. Without that point of comparison that people can agree upon decisions about what meets, and does not meet, a “standard” are subjective.
That’s why the first questions when troubleshooting any kind of issue should be forms of “What is the standard?” For example, “What is the quality specification?” “What is the boundary between ‘acceptable’ and ‘not acceptable?” What is the standard process? Did we follow it? Or did something get in the way?
If the answer to any of these questions is “we don’t know” or disagreement, then the work to be done is clear: Define the standard, then begin again. If you are following the Toyota Kata structure, every layer is a possible target condition that must be developed, tested, and validated through experimentation.
Once everyone agrees, then you have institutional knowledge, not just the opinion of an expert.
Back to Step 4: True Root Cause
When I went through my jidoka model above, I mentioned that “putting out the fire” and even rebuilding was Step 3.
If you traced your product defects back to damaged or worn tooling, and fixed the tooling, you have restored to the original standard. That’s Step 3.
What remains to be done, though, is keep digging.
What did we miss? Why did we have to produce a defective product before we noticed something was amiss? Was there some kind of exceptional step earlier that damaged that tooling earlier? If so, then why did the Team Member feel the obligation to try a work-around rather than STOP, and getting someone’s attention? “Hey, this isn’t right.”
Maybe it was damaged during a cleaning process. (I’m obviously making this stuff up.) Why? Were the right tools or materials not available? I’ve seen that when a well meaning machine operator was trying to do routine cleaning, but the regular cleaning stuff wasn’t available, so he grabbed something similar and proceeded. But that stuff ended up slowly dissolving seals, eventually causing expensive bearing failure.
What was the standard? Did it specify what material to use? Or was it just ad-hoc instructions that left the details ambiguous, because “that’s just what everyone uses?”
What did the machine’s manufacturer say? (They were very clear in the fine print, but nobody reads that stuff… oops, no warranty for you.)
Keep Learning
Key here is that you will never think of everything. The only protection you have is a culture where the default response when something doesn’t seem right is to STOP and get clarity. Relentlessly drive ambiguity out of your processes, out of your specifications, out of your standards. (And take time, now and again, to step back and challenge everything to SIMPLIFY, as complexity creeps in.)
*England did not adopt the Gregorian calendar until 1752. By that calendar, the date would be 5 September.