I’m writing up a proposal for a benchmarking and study week, and just typed the term “push improvement” as a contrast to a true “continuous improvement culture.” I wanted to explore that a bit here, with you, and perhaps I’ll fill in the idea in my own mind.
Push Improvement
A few years ago I was working with a few sites of a multi-national corporation. In one of their divisions, their corporate lean office was pushing various programs into place. Each site was required to implement, and was graded on:
- 5S
- Jidoka
- Heijunka
- Toyota Kata
plus a few other things. Those are the ones I really remember. Each of these programs was separate and distinct, they had been deployed on some kind of phased time-table over a few years. They also had requirements to maintain some number of Six-Sigma Black Belts and Green Belts in their facilities, with the requirement to report on a number of projects.
They brought me in to teach the Toyota Kata stuff.
In reality, while people taking the class generally thought it was worthwhile, the leadership teams were also a little resentful that all of this stuff was being, in the words of one plant manager, “pushed down our throats.”
Even the Toyota Kata “implementation” had a specific sequence of steps that the site was expected to check off and report their progress on. In addition, there were requirements for how the improvement boards would look, including the position of the corporate logo and the colors used – all in the name of “standardization.”
At the same time, of course, the plants were also measured on their performance – financial, delivery, quality, etc. These metrics were separate and distinct from their audit scores on all of the lean stuff.
On the shop floor, they had the artifacts in place – the boards, the charts, the lines on the floor, but were struggling with making it all work. There was no integration into the management system. Each of these was a program.
I should also point out that, ironically, the plant that was getting the most traction with continuous improvement at the time was the one that was pushing back the hardest against this rote, “standard” approach.
A few years before that, I had been working (as an employee) in another multi-national company. There was a big push from the executives at the very top to develop a set of metrics they could use to determine if a site was “doing lean correctly.” They wanted a set of measurements they could monitor from corporate headquarters that would ensure that any business performance improvement was the result of “doing lean” rather than something else.
Both of these organizations were looking at this as an issue with compliance rather than developing their leaders.
Implementations like these typically involve things like:
- Developing some kind of “curriculum” and rolling it out.
- Requiring sites to have a “value stream map” and a “lean plan.”
- Audits and “lean assessments” against some kind of checklist.
- Monitoring the level of activity, such as how many kaizen events sites are running.
I have also seen cases of an underlying assumption that “if only we can explain it well enough, then managers will understand and do it.” This assumption drives building models and diagrams that try to explain how everything works, or the relationships between the tools. I’ve seen “pillar models,” puzzles, gears, notional value stream maps, and lots of other diagrams.
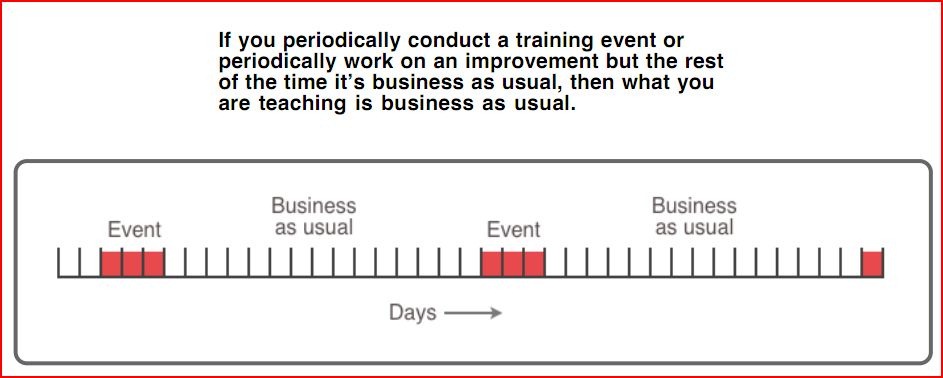
In summary, “push improvement” is present when implementing an improvement program is the goal. Symptoms are things such as a project plan with milestones for specific “lean tools” to be in place.
The underlying thinking is that you are doing improvement because you can, not because you must.
This is, I believe, what Jeff Liker and Karyn Ross refer to as mechanistic lean in their book The Toyota Way to Service Excellence.
Relationship to the Status Quo
One of the obstacles that organizations face with this approach is the traditional relationship to the status quo. Most business leaders are trained to evaluate any change against a financial return based on the cost. In other words, we look at the current level of performance as a baseline; evaluate the likely improvement; look at what it would cost to get to that new level and ask “Is it worth doing this?”
If the answer comes up short of some threshold of return, then the answer is “no,” and the status-quo remains as a rational optimum.
Implication: The status-quo is OK unless there is a compelling reason to change it.
For the lean practitioner, this presents a problem. We have to convince management that there is a short-term return on what we are proposing to do in order to justify the effort, time and expense. Six Sigma black belt projects are intently focused on demonstrating very high cost benefit, for example. And, honestly, if you are spending the money to bring in a consultant from Japan and an interpreter, I can see wanting some assurance there is a payback.1
If the discussions are around “What improvements can we make?” and then working up the benefit, you are in this trap. Those benefits, by the way, rarely find their way to the actual P&L unless there is already a business plan to take advantage of them.
The root cause of this thinking may well be disconnection of continuous improvement from whatever challenges the organization is facing; coupled with assumptions that a “continuous improvement program” can be implemented as a project plan on a predictable timeline.
Pull Improvement
Solving Problems
The purpose of any improvement activity is to solve problems. Real problems. In my classes, I often ask for a show of hands from people who have a shortage of problems on a daily basis. I never get any takers. Since there are usually lots of problems – too many to deal with all of them – we need to be careful to work on the right ones. The ROI approach I talked about above is a common way to sort through which ones are worth it. We can also get locked into “Pareto Paralysis”
So which ones should we work on?
Inverting this question, when someone wants to make a change, put in a “lean tool,” etc., my question is “What problem are you trying to solve?” And “we don’t have standard work” is not a problem, it is lack of a proposed solution. In these cases I might ask “…. and therefore?” to try to understand the consequence of this “lack of…” The problem might be buried in there somewhere. But if the issue at hand is trying to raise an audit score for its own sake, we are pack to “Push Improvement.”
A meeting gets derailed pretty fast when people are debating which solution should be applied without first agreeing on the problem they are solving. The Coaching Kata question “Which one [obstacle] are you addressing now?” is intended to get help the learner stay clear and focused on this.
But long before we are talking about problems, we need to know where we are trying to end up. This is why the idea of a clear and compelling challenge is critical.
Challenge First
Organizations that are driven by continuous improvement have a different relationship with the status-quo. Those organizations always have a concrete challenge in front of them. In other words, the status-quo is unacceptable. “Today is the worst we will ever be.”
Cost enters into the discussion when looking at possible ways to reach that destination. But it does not drive the decision about whether or not to try. That decision has already been made. The debate is on how to do it.
The Challenge with Challenges
“Wait a minute… we have objectives to reach too!” Yes, lots of organizations set out objectives for the year or longer. Here are some of the scenarios I have seen, and why I think they are different.
The goal setting is bottom-up. The question “What can we improve?” cascades down the organization, and individual managers set their goals for the year and roll them back up. There may be a little back-and-forth, and discussion of “stretch goals,” but the commitment comes from below. In most of the cases I have seen these goals are carefully worded, the measurements delicately negotiated, with bonuses riding on the level of attainment of these objectives. I have used the word “goal” here because these are rarely challenges or even challenging.
The goal is based strictly on hitting metrics. I have discussed the dangers of “management by measurement” a few times in the past.
A pass is given if there is a strong enough justification made for missing the goal. Thus the incentive to carefully define the metrics, and include caveats and loopholes.
There are measurements but not objectives. Any improvement is OK.
Any true challenge is labeled as a “stretch goal” meaning “I don’t really expect you to be able to reach it.”
And, sometimes the end of the year is an exercise in re-negotiating the definition of “success” to meet whatever has been achieved.
None of this is going to drive continuous improvement, nor align the effort toward achieving something remarkable or “insanely great.”
But here is the biggest difference: FEAR.
Fear of failure. Fear of committing to something I don’t already know how to achieve. Fear of admitting “I don’t know.”
And fear breeds excuses and other victim language that makes sure success or failure was beyond my control.
Fearless Challenges
So maybe that’s it. The key difference is fearless challenge. So what would that look like?
Here I defer to Jeff Liker and Gary Convis’s great book The Toyota Way to Lean Leadership. But I have seen this in action elsewhere as well.
Some key differences here:
- The challenge comes from above. It isn’t a bottom-up “what can we improve?” It is a top-down “This is what we need to be able to do.”
- It is an operational need, not a process specification. In other words, it isn’t the “lean plan.” The process specification is what is created to meet the challenge.
- The challenge is an integral part of developing people’s capability. Perhaps this is the key difference.
- There is no fear because the challenge comes with active support to meet it. That support, if done well, is both technical and emotional. We’re in this together – because we are.
Improvement = Meeting the Challenge
Given that there is a business or operational imperative established, we are no longer trying to push improvement for its own sake. We have an answer to “Why are we doing this?” beyond “to get a higher 5S score.”
Now there is a pull.
In my Toyota Kata class, I give the teams a challenge that, in the moment, is seemingly impossible. That is intentional. I hear air getting sucked in through teeth. “No way!” is usually the reply when I ask how it feels.
Then, for the next few hours, the teams are methodically guided through:
- Grasping the current condition – understanding their process as a much deeper level.
- Breaking down the problem into pieces, taking on one at a time. First a target condition, then specific obstacles.
Depending on how much time they have, 1/4 to 1/3 of the teams crack the problem, a few excel and go beyond, and those that don’t usually acknowledge they are close.
The teams that get there fastest are the ones who get into a quick cadence of documented experiments and learning. They see the problems they must solve much quicker, and figure out what they need to do. I tell them at the start, as I hold up my blank Experiment Records, “The teams that get it are the ones who burn through these the quickest.”
In the process of tackling the challenge, they learn what continuous improvement is really about. I don’t specify their solution. Any hints I give are about what to pay attention to, not what the solution looks like. I don’t deploy tools or give them a template for the solution. At the same time, most teams converge on something similar, which isn’t surprising.
Taking this to the real world – I see similar things. Teams taking on similar challenges on similar processes often arrive at similar looking solutions. But each got there themselves, for their own reasons, often following quite different paths.
While it seems more efficient to just tell them the answers, it is far more effective to teach them how to solve the problem. That is something they can take beyond the immediate issue and into other domains.
Pull Improvement = Meeting a Need
In my post Learning to See in 2013, I posed the question nobody asks: Why are you doing this at all? I point out that, in many cases, value-stream mapping is used as a “what could we improve?” tool, which is backwards from the original intent.
If there is a clear answer to “Why are we doing this?” or, put another way, “What do we need to be able to do that, today, we can’t?” or even “What experience do we aspire to deliver to our customers that, today, we cannot?” then everything else follows. Continuous Improvement becomes a daily discussion about what steps are we taking to get there, how are we doing, what are we learning, what do we need to do next (based on what we learned)?
This is pull. The people responsible for getting a higher level of performance are pulling the effort to get things to flow more smoothly. The mantra here is “not good enough,” but that must be the form of a challenge that inspires people to step up, not punitive.
Then it’s easy because “they” want to do it.

Epilogue: For the Practitioner
If you are reading this, you are likely a practitioner – someone on staff who is responsible for “continuous improvement” in some form, but not directly responsible for day-to-day operations. I say that because I know, in general, who my subscribers are.
This concept presents a dilemma because while you are challenged with influencing how the organization goes about improving things, the challenge of what improvements must be made (if it exists at all) is disconnected from your efforts.
That leaves you with trying to “drive improvement into the organization” and “be a change agent” and all of those other buzzwords that are probably in your job description.
Here are some things to at least think about that might help.
Let go of dogma. If you think continuous improvement is only valid if a specific set of tools or jargon are used, then you are already creating resistance for your efforts.
Focus on learning rather than doing. You don’t have all of the answers. And even if you did, you aren’t helping anyone else by just telling them what to do. No matter how much sense it makes to you, logical arguments are rarely persuasive, and generally create a false “yes.”
Seek first to understand. Listen. Paraphrase back. Try to get the words “Yeah, that’s right.” to come out of that resistant manager you are dealing with. Remember your purpose here is to help line leadership meet their challenges. Often those challenges are vague, are negative – as in trying to avoid some consequence – or even expressed as implied threats. You don’t have to agree, but you do need to “get it.”
That’s the first step to rapport, which in turn, is necessary to any kind of agreement or real cooperation. As a friend of mine said a long time ago: “You can always get someone’s attention by punching them in the nose, but they likely aren’t going to listen to what you have to say.” Making someone wrong is rarely going to increase their cooperation.
All of this, by the way, is harder than it sounds. I’m still learning these lessons, sometimes multiple times. I’ve been on my own journey of explicit / deliberate learning here for a couple of years.
We have a couple of generations now of improvement practitioners who have been trained with the idea that “lean is good” (or Six Sigma is good, or Theory of Constraints is good, or…). Therefore, it follows, that these things need to be put into place for their own sake – because all of the best companies do them.
This approach, though, reflects (to me) a shallow understanding of what continuous improvement is all about. It skips the “Why?” and goes straight to “How” and “What.” My experience has also been that relatively few of the practitioners steeped in this can actually articulate how the mechanics of these systems actually drive improvement on a daily basis after all of the mechanics are in place beyond a superficial statement like “people would see and remove waste.”
It seems that implementing the mechanics is equated with improvement, when in reality, those mechanics are simply an engine for starting improvement.
Yes, the mechanics are important, but the mechanics are not the reason. We are leaving out the people when we have these discussions. What are they doing every day (other than “following their standard work”)? How do these mechanics actually help them move, as a team, toward a goal they cannot otherwise attain?
————–
1In its worst manifestation, this thinking can be a cancer on the integrity of the company, for example, GM has had a couple of scandals where it has been revealed that they calculated the ROI of fixing a safety defect vs. the cost of paying off wrongful death lawsuits. Don’t even go there!
 “Are you ahead or behind?” seems an innocent enough question.
“Are you ahead or behind?” seems an innocent enough question.